WITRAN代码复现¶

约 2729 个字 99 行代码 1 张图片 预计阅读时间 15 分钟
简单复现,只复现模型部分,看明白数据流动,收回我的话,这个代码太难了,有各种门,我不熟
WITRAN_2DPSGMU_Encoder¶
- 维护各种门
首先这个类的 forward 接收:输入张量 input、batchsize,inputsize 每小时记录的特征数,flag 用于控制调整维度
进入函数,首先是根据 flag 调整维度,这里 flag=0,将输入 input 的维度从[4,32,24,11] permute成[4,32,24,11],具体的实际含义作者说是按照自然周期对时序数据进行列重排,这里是小时级别的数据,因此 96 个小时记录的 4 天 24 小时的数据,因此重排成 [4,32,24,11]
Water2sea_slice_num, _, Original_slice_len, _ = input.shape
'''
获取调整维度后的形状 切片数(4、4 天)、原始切片长度(24 小时)
Water2sea_slice_num = 4 ,Original_slice_len = 24
'''
Water2sea_slice_len = Water2sea_slice_num + Original_slice_len - 1
'''
计算扩展后的序列长度 Water2sea_slice_num = 4,Original_slice_len = 24
Water2sea_slice_len = 24 + 4 - 1 = 27
切片长度 = 切片数 + 原始切片长度 - 1
'''
接下来对 input 的形状进行解包操作,得到转二维时序数据的行数和列数,我们原始得到的行数是 4,列数是 24,但作者为了让时间点连续,实际使用的列是 27,也就是说 4+24-1=27
说明:关于这个 27 可以详细说明作者为什么这么处理,因为后面涉及到填充操作
作者为了让时间点连续,使用滑动窗口的方式扩展列数: 第 1 天的数据从第 0 列开始。 第 2 天的数据从第 1 列开始。 第 3 天的数据从第 2 列开始。 第 4 天的数据从第 3 列开始。 原始输入 [32, 4, 24, 11] 被调整为 [4, 32, 24, 11],按照天数和小时组织。后面 扩展后的列数 27 包含了原始的 24 小时数据,并在时间维度上引入了 3 小时的重叠。 更形象的表示: 假设有 4 天的数据,每天 24 小时,每小时有 11 个特征: 第 1 天:[特征1, 特征2, ..., 特征11],共 24 小时。 第 2 天:[特征1, 特征2, ..., 特征11],共 24 小时。 第 3 天:[特征1, 特征2, ..., 特征11],共 24 小时。 第 4 天:[特征1, 特征2, ..., 特征11],共 24 小时。 扩展后的数据 通过滑动窗口的方式,每一天的数据与前一天的数据在时间维度上产生了重叠: 第 1 天:[0:24],表示第 1 天的 24 小时数据。 第 2 天:[1:25],表示第 2 天的 24 小时数据,与第 1 天的数据重叠 1 小时。 第 3 天:[2:26],表示第 3 天的 24 小时数据,与第 2 天的数据重叠 2 小时。 第 4 天:[3:27],表示第 4 天的 24 小时数据,与第 3 天的数据重叠 3 小时。
hidden_slice_row = torch.zeros(Water2sea_slice_num * batch_size, self.hidden_size).to(input.device)
'''
初始化行和列的隐藏状态
输入: Water2sea_slice_num = 4,batch_size = 32,hidden_size = 32
处理:torch.zeros
输出: hidden_slice_row : [4 * 32, 28] = [128, 32]
'''
hidden_slice_col = torch.zeros(Water2sea_slice_num * batch_size, self.hidden_size).to(input.device)
'''
存储每个时间步的列隐藏状态
输入:
Water2sea_slice_num = 4,batch_size = 32,self.hidden_size = 32
处理:torch.zeros
输出:
hidden_slice_col = [128, 32]
'''
接下来初始化行隐藏状态和列隐藏状态
先说结论,行隐藏状态的形状是 [128,32],128 表示 4×32,4 表示 4 天,要为 每一天维护一个隐藏状态,又因为 batchsize=32,每一天的数据需要为每个样本维护一个隐藏状态,用于捕获时间序列的特征信息,所以一共维护 128 个隐藏状态,每个隐藏状态的维度是 32。
这里 4 天,代码中的变量定义为 Water2sea_slice_num 切片数,batchsize 不说了,self.hidden_size=32
现在看列隐藏状态,形状[128,32],与行隐藏状态同理
其实我以为列隐藏状态维护的是小时的,24×32
input_transfer = torch.zeros(Water2sea_slice_num, batch_size, Water2sea_slice_len, input_size).to(input.device)
下一句,0 初始化输入张量,这个张量的形状是[4,32,27,11],4 是 4 天,32 个样本数,27 是为了让时间点连续,作者通过滑动窗口的方式扩展序列长度,计算方式是前面那句 Water2sea_slice_len = Water2sea_slice_num + Original_slice_len - 1。例如,Water2sea_slice_len = 4 + 24 - 1 = 27
扩展序列长度的目的是 在时间维度上产生重叠,捕获时间序列的连续性。
接下来遍历 4 天
目的是为了将原始输入填充到扩展后的张量中
具体来说,原始输入 input 的形状为 [4, 32, 24, 11] ,扩展序列记为 input_transfer ,形状为 [4, 32, 27, 11] 用 24 个小时的数据填充这个 27,每次挪动 r 步,用图表示:
input_transfer[0, :, :, :]:
| H1 H2 H3 ... H24 0 0 0 |
input_transfer[1, :, :, :]:
| 0 H1 H2 ... H24 0 0 |
input_transfer[2, :, :, :]:
| 0 0 H1 ... H24 0 |
input_transfer[3, :, :, :]:
| 0 0 0 H1 ... H24 |
原始输入的序列长度为 24,通过滑动窗口填充,扩展为 27。
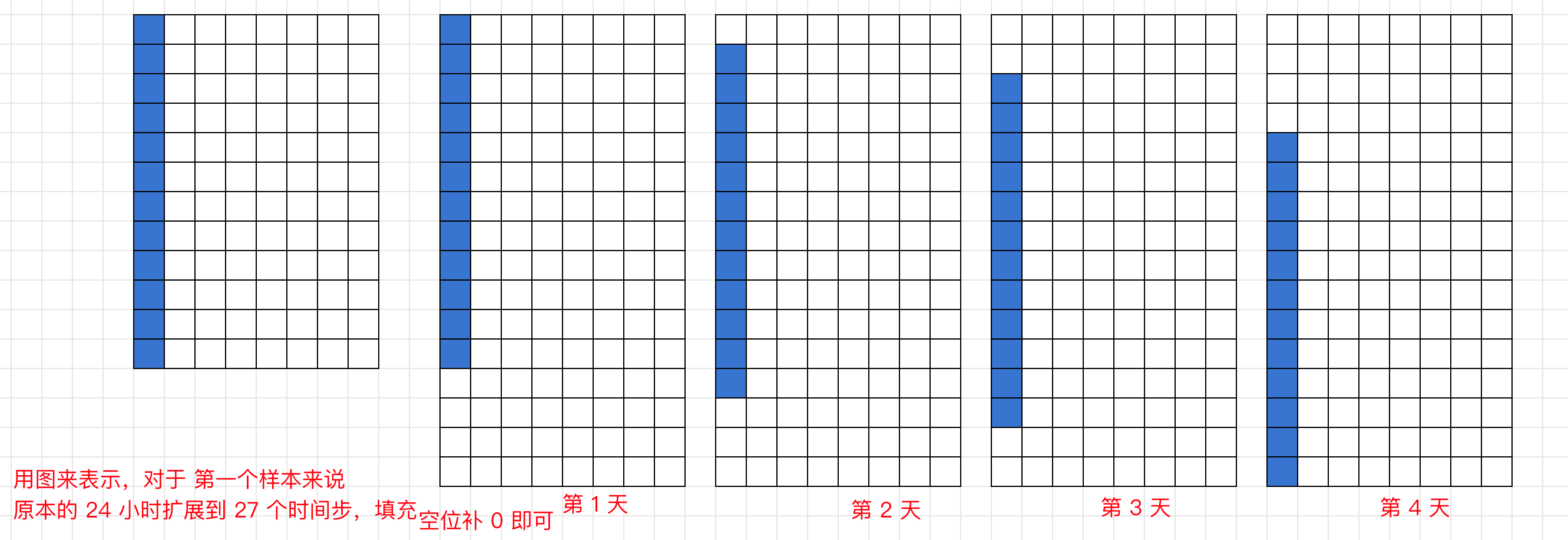
遍历 r 也就是天,填充的位置从 r 开始,到 填紧随其后的 Original_slice_len 原始切片长度。
再说一遍
> 也就是原本的第 1 天从第1 个位置开始,第 2天从第1 个位置开始,第 3天从第1 个位置开始,第 4天从第1 个位置开始,每天有 24 个位置,现在为了时间连续,对每天进行填充,填充后的第一天从第1 个位置开始,填原始的 24 小时数据,填充后的第二天从第 2 个位置开始,填原来第二天的 24 小时,填充后的第 3 天从第 3 个位置开始,填原来第 3 天的 24 小时数据,填充后的第 4 天从第 4 个位开始,填原来的 24 小时数据,如果是对应到 python 的索引,就把前面所有第减去 1 就行。
接下来是初始化行隐藏状态列表和列隐藏状态列表
接下来开始 遍历 self.num_layers = 3
设置层数=3,
遍历到第一层时,
使用扩展后的输入张量 input_transfer 作为输入, 输入是 a,形状为 [128, 27, 11] 将 4 天,每天的 32 个样本合并,所以是 128 个状态需要更新,嵌入到 hiddensize= 32 维。
输入 a 的形状 [128, 27, 11]:表示 128 个样本(4 天 × 每天 32 个样本)、27 个时间步、每个时间步 11 个特征,通过线性变换将输入特征(11 维)映射到隐藏状态的特征空间(32 维)。关于这个 a的详细处理后面会说。
第一层的权重 W,使用初始化的权重 self.W_first_layer ,定义在 init
self.W_first_layer = torch.nn.Parameter(torch.empty(6 * hidden_size, input_size + 2 * hidden_size))
这个权重是初始化了所以需要的权重,初始化权重的形状是
[6 * hidden_size, input_size + 2 * hidden_size]
为什么是这个形状?
6 * hidden_size表示模型中需要生成 6 个门控信号、每个门的大小为 hidden_sizeinput_size + 2 * hidden_size表示输入特征的数量,输入特征由 3 个部分组成:①input_size:当前时间步的输入特征②hidden_size:行隐藏状态(hidden_slice_row)③hidden_size:列隐藏状态(hidden_slice_col)
为什么是 6 个门呢?
- 首先,每个门都要维护行隐藏状态和列隐藏状态
- 那一共要维护 3 个门,分别是输入门、输出门、更新门
- 所以是 6 个门
具体来说
具体来说
更新门(Update Gate)
- 用于控制隐藏状态中保留多少来自上一时间步,多少来自当前时间步的输入;
- 包括:update_gate_row(行方向更新门)、update_gate_col(列方向更新门)
输出门(Output Gate):
- 用于控制隐藏状态的输出强度。
- 包括:output_gate_row(行方向输出门)、output_gate_col(列方向输出门)
输入门(Input Gate):
- 用于生成隐藏状态的候选值。
- 包括:input_gate_row(行方向输入门);input_gate_col(列方向输入门)。
总共需要生成 6 个门的信号,因此输出特征的数量为 6 * hidden_size
那输入特征的形状 input_size + 2 * hidden_size
表示在每个时间步,模型需要结合当前时间步的输入特征和隐藏状态来生成门控信号。输入特征的组成有:
- **input_size:**当前时间步的输入特征;
- hidden_size(行隐藏状态):表示上一时间步的行隐藏状态(hidden_slice_row);
- hidden_size(列隐藏状态):表示上一时间步的列隐藏状态(hidden_slice_col);
因此,总的输入特征数量为 input_size + 2 * hidden_size。
好,以上完成了 第一层时,怎么获得初始化的状态与权重
也就是这里:
if layer == 0:
'''
layer = 0 第一层使用扩展后的输入张量作为输入
'''
a = input_transfer.reshape(Water2sea_slice_num * batch_size, Water2sea_slice_len, input_size)
'''
输入:Water2sea_slice_num=4,batch_size=32,Water2sea_slice_len27,input_size=11
处理:.reshape
输出:a [128,27,11]
'''
W = self.W_first_layer
'''
输入:self.W_first_layer = torch.nn.Parameter(torch.empty(6 * hidden_size, input_size + 2 * hidden_size))
输入 hidden_size=32,input_size=11
处理:torch.nn.Parameter(torch.empty(
输出:self.W_first_layer [192,75]
输出:W = self.W_first_layer = [192,75]
'''
那如果不是第一层呢?接下来看 else:
还是先得到每层的输入 a,比如第二层的输入会接收上一层的输出 output_all_slice,并进行 dropout 防止过拟合。
这里所涉及的每个输入解释:
(1)关于这个 output_all_slice 形状是 [128, 27, 64]
这里涉及的每个数字的解释
- 128:总样本数(4 天 × 每天 32 个样本)
- 27:扩展后的时间步数。
- 64:拼接后的隐藏状态特征维度(
2 * hidden_size,即行隐藏状态和列隐藏状态各 32 维)
(2)第二个输入:self.dropout
- Dropout 的概率,例如 0.05,表示在训练过程中,每个神经元有 5% 的概率被随机置为 0。
(3)第三个输入:self.training:
- 表示当前是否处于训练模式。
- 如果为 True,则执行 Dropout 操作;如果为 False(推理模式),则不执行 Dropout。
这句就是 对上一层的输出 output_all_slice 进行 Dropout 操作
输入 上一层的输出形状为 [128, 27, 64],F.dropout不会改变形状,所以 输出形状 a 的形状也是 [128, 27, 64]
这里输入的含义,输出的含义,每个数字的含义,处理的含义都说了,清清爽爽
这里的 if-else 是关于每层输入 a和权重 的处理,
首先关于输入 a:如果是第一层的 a 对原始扩展输入张量 input_transfer reshape一下,如果是其它层比如第二层的输入 a,就是对上一层的输出 output_all_slice 进行 dropout,随机失活一部分输入节点,同时需要注意如果是推理模式的话,不进行 dropout,输入 a 的形状,如果是第一层 [128,27,11],如果是其它层输入a 的形状 [128, 27, 64]
注意区分这里每个数字的含义:
- 128:总样本数(4 天 × 每天 32 个样本),将天数和批次大小合并为一个维度。
- 27:扩展后的时间步数。
- 11:每个时间步的特征维度
- 64:拼接后的隐藏状态特征维度(2 × hidden_size,即行隐藏状态和列隐藏状态各 32 维)。
说句题外话,RNN 的标准输入就是
NTC,N 也可以记作 B 表示几个样本,T 表示一个样本几个时间步,C 表示每个时间步的特征数,标准输出是,[层数×方向,样本数,隐藏层维度]
继续看 else,还有权重没说
if layer == 1:
layer0_output = a # 保存第一层的输出,用于残差连接
'''
输入:
a [128, 27, 64](第一层的输出)
处理:
将第一层的输出保存到 layer0_output 中,用于后续层的残差连接。
输出:
layer0_output [128, 27, 64]
'''
如果是第一层的话,还要保存第 0 层的输出,用于后续残差连接的处理
这里想说的是
- 第 index= 0 层的输入
[128,27,11],第 0 层的输出反而是[128, 27, 64] - 仿照 RNN 的理解,原始的 [N,T,C],经过 RNN 输出,[N,T,HiddenDim],如果单独取最后一个时间步的隐藏状态就是 [层数×方向,N,HiddenDim]
- 这里的 64 是行隐藏状态(32)+列隐藏状态(32)
好,下一行:
W = self.W_other_layer[layer-1, :, :] # 其他层的权重矩阵
'''
输入:
self.W_other_layer [2, 192, 128](其他层的权重矩阵,形状为 [num_layers-1, 6 * hidden_size, 4 * hidden_size])
layer-1(当前层的索引减 1,用于选择对应层的权重矩阵)
处理:
提取当前层的权重矩阵 W。
输出:
W [192, 128](当前层的权重矩阵)
'''
初始化权重
先看其它层权重矩阵的定义: