自总:扒模块¶

约 354 个字 467 行代码 2 张图片 预计阅读时间 8 分钟
Autoformer 序列分解模块¶
模块图数据流动:
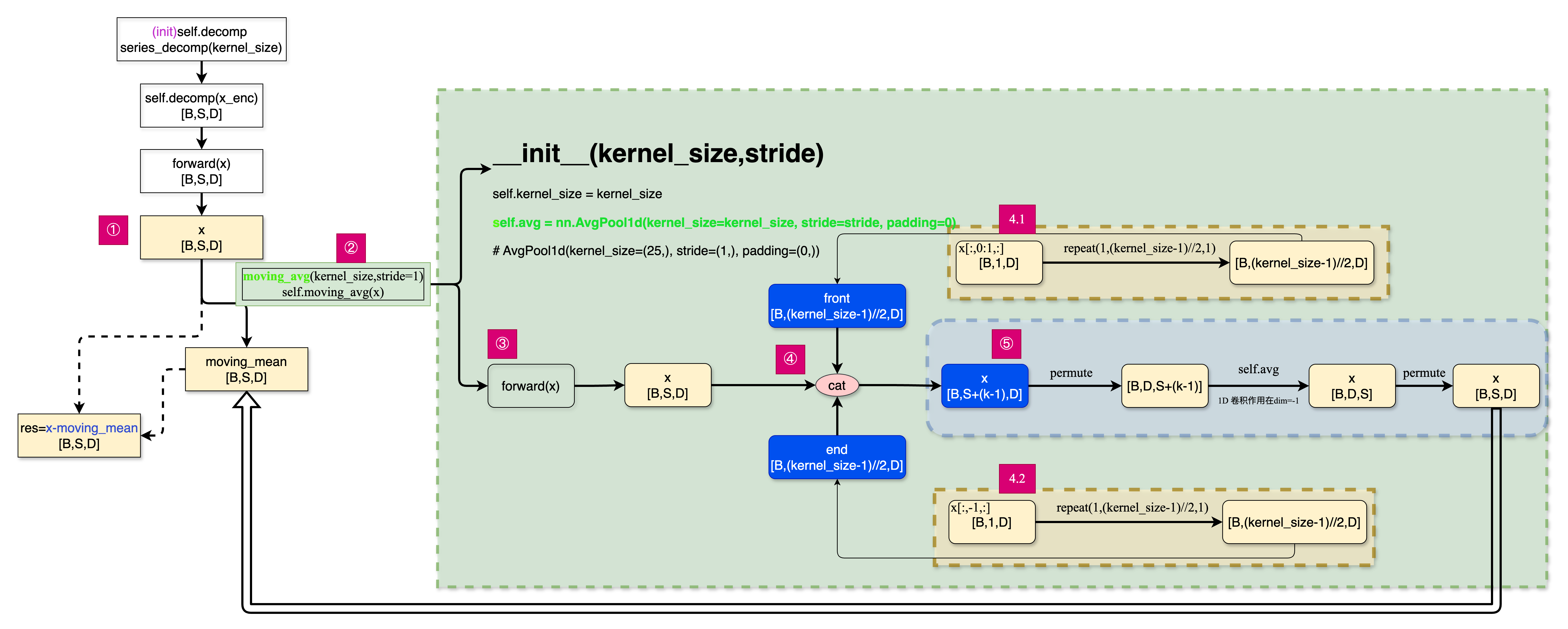
代码摘出:
使用说明:
Bash
输入序列形状[B,S,D]: torch.Size([32, 96, 7])
季节性分量形状[B,S,D]: torch.Size([32, 96, 7])
趋势性分量形状[B,S,D]: torch.Size([32, 96, 7])
- 输入输出形状相同
- 在提取趋势性分量时,用的移动平均,同时提取的第一个时间和最后一个时间步进行了 复制填充,保证 移动平均以后输入和输出序列长度保持不变
- 季节性分量直接是
原始序列 - 趋势性分量 - 按照实际情况,修改
B, L, D = 32, 96, 7和kernel_size = 25即可 - 1D avgPool 作用在
dim = -1
Python
import torch
import torch.nn as nn
import torch.nn.functional as F
class moving_avg(nn.Module):
"""
Moving average block to highlight the trend of time series
"""
def __init__(self, kernel_size, stride):
super(moving_avg, self).__init__()
self.kernel_size = kernel_size
self.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=stride, padding=0) # AvgPool1d(kernel_size=(25,), stride=(1,), padding=(0,))
def forward(self, x):
# padding on the both ends of time series
# 提取第一个时间步并重复,用于前端填充 x.shape = [32, 36, 7]
# [B, L, D] -> [B, 1, D] -> [B, (kernel_size-1)//2, D]
front = x[:, 0:1, :].repeat(1, (self.kernel_size - 1) // 2, 1)
# 提取最后一个时间步并重复,用于后端填充
# [B, L, D] -> [B, 1, D] -> [B, (kernel_size-1)//2, D]
end = x[:, -1:, :].repeat(1, (self.kernel_size - 1) // 2, 1)
# 连接填充部分与原序列
# [B, (k-1)//2, D] + [B, L, D] + [B, (k-1)//2, D] -> [B, L+(k-1), D]
x = torch.cat([front, x, end], dim=1)
# 转置并应用一维平均池化
# [B, L+(k-1), D] -> [B, D, L+(k-1)] -> [B, D, L]
# 池化窗口大小为kernel_size,步长为1,输出长度为(L+(k-1)-k+1)=L (length + 2P - K + 1)
x = self.avg(x.permute(0, 2, 1))
# 转置回原始维度顺序 [B, D, L] -> [B, L, D]
x = x.permute(0, 2, 1)
return x
class series_decomp(nn.Module):
"""
Series decomposition block
"""
def __init__(self, kernel_size):
super(series_decomp, self).__init__()
self.moving_avg = moving_avg(kernel_size, stride=1)
def forward(self, x):
# 计算移动平均,提取序列趋势分量
# x 形状[B, L, D] -> moving_mean形状[B, L, D]
# moving_avg内部会进行填充,保证输出形状与输入相同
moving_mean = self.moving_avg(x)
# 通过原始序列减去趋势分量,得到残差(季节性分量),逐元素减法操作
# x形状[B, L, D] - moving_mean形状[B, L, D] -> res形状[B, L, D]
res = x - moving_mean
# 返回季节性分量和趋势分量,均保持原始形状[B, L, D]
# 第一个返回值res是季节性分量,第二个返回值moving_mean是趋势分量
return res, moving_mean
# init
# Decomp
kernel_size = 25
decomp = series_decomp(kernel_size)
B, L, D = 32, 96, 7
# forward
x_enc = torch.randn(B, L, D )
# 对输入序列进行时间序列分解,将x_enc[B, L, D]分解为季节性和趋势成分,形状保持不变
seasonal_init, trend_init = decomp(x_enc) # 均为[B, L, D]
print("输入序列形状:",x_enc.shape)
print("季节性分量形状:",seasonal_init.shape)
print("趋势性分量形状:",trend_init.shape)
SegRNN 序列分段¶
数据流动图
输入&输出
说明:
- 来源:SegRNN github
- 需要的参数:
batch_size、 seq_len 、enc_in - 特别的参数:
seg_len表示分段长度,具体分几段在代码中的 init 中计算。 - 该代码配置时 使用命令行参数进行配置
- 后面备份了多样化配置:使用多卡进行训练
- 输入和输出分别是什么意思:输入不多说了,输出的是[B,P,D],就是根据给定的输入序列预测的未来时间步
- 这里的位置编码,也可以
Python
'''
Concise version implementation that only includes necessary code
'''
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self, configs):
super(Model, self).__init__()
# get parameters
self.seq_len = configs.seq_len
self.pred_len = configs.pred_len
self.enc_in = configs.enc_in
self.d_model = configs.d_model
self.dropout = configs.dropout
self.seg_len = configs.seg_len
self.seg_num_x = self.seq_len//self.seg_len
self.seg_num_y = self.pred_len // self.seg_len
self.valueEmbedding = nn.Sequential(
nn.Linear(self.seg_len, self.d_model),
nn.ReLU()
)
self.rnn = nn.GRU(input_size=self.d_model, hidden_size=self.d_model, num_layers=1, bias=True,
batch_first=True, bidirectional=False)
self.pos_emb = nn.Parameter(torch.randn(self.seg_num_y, self.d_model // 2))
self.channel_emb = nn.Parameter(torch.randn(self.enc_in, self.d_model // 2))
self.predict = nn.Sequential(
nn.Dropout(self.dropout),
nn.Linear(self.d_model, self.seg_len)
)
def forward(self, x):
# b:batch_size c:channel_size s:seq_len s:seq_len
# d:d_model w:seg_len n:seg_num_x m:seg_num_y
batch_size = x.size(0)
# normalization and permute b,s,c -> b,c,s
seq_last = x[:, -1:, :].detach()
x = (x - seq_last).permute(0, 2, 1) # b,c,s
# segment and embedding b,c,s -> bc,n,w -> bc,n,d
x = self.valueEmbedding(x.reshape(-1, self.seg_num_x, self.seg_len))
# encoding
_, hn = self.rnn(x) # bc,n,d 1,bc,d
# m,d//2 -> 1,m,d//2 -> c,m,d//2
# c,d//2 -> c,1,d//2 -> c,m,d//2
# c,m,d -> cm,1,d -> bcm, 1, d
pos_emb = torch.cat([
self.pos_emb.unsqueeze(0).repeat(self.enc_in, 1, 1),
self.channel_emb.unsqueeze(1).repeat(1, self.seg_num_y, 1)
], dim=-1).view(-1, 1, self.d_model).repeat(batch_size,1,1)
_, hy = self.rnn(pos_emb, hn.repeat(1, 1, self.seg_num_y).view(1, -1, self.d_model)) # bcm,1,d 1,bcm,d
# 1,bcm,d -> 1,bcm,w -> b,c,s
y = self.predict(hy).view(-1, self.enc_in, self.pred_len)
# permute and denorm
y = y.permute(0, 2, 1) + seq_last
return y
# init
import argparse
parser = argparse.ArgumentParser(description='Model family for Time Series Forecasting')
# forecasting task
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length')
parser.add_argument('--pred_len', type=int, default=96, help='prediction sequence length')
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size') # DLinear with --individual, use this
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
parser.add_argument('--dropout', type=float, default=0.5, help='dropout')
parser.add_argument('--seg_len', type=int, default=48, help='segment length')
args = parser.parse_args()
model = Model(args).float()
batch_x = torch.randn(args.batch_size,args.seq_len,args.enc_in)
# forward
outputs = model(batch_x)
print("输入序列形状[B,S,D]: ",batch_x.shape)
print("outputs.shape[B,P,D]:",outputs.shape)
多卡训练
Python
'''
Concise version implementation that only includes necessary code
'''
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self, configs):
super(Model, self).__init__()
# get parameters
self.seq_len = configs.seq_len
self.pred_len = configs.pred_len
self.enc_in = configs.enc_in
self.d_model = configs.d_model
self.dropout = configs.dropout
self.seg_len = configs.seg_len
self.seg_num_x = self.seq_len//self.seg_len
self.seg_num_y = self.pred_len // self.seg_len
self.valueEmbedding = nn.Sequential(
nn.Linear(self.seg_len, self.d_model),
nn.ReLU()
)
self.rnn = nn.GRU(input_size=self.d_model, hidden_size=self.d_model, num_layers=1, bias=True,
batch_first=True, bidirectional=False)
self.pos_emb = nn.Parameter(torch.randn(self.seg_num_y, self.d_model // 2))
self.channel_emb = nn.Parameter(torch.randn(self.enc_in, self.d_model // 2))
self.predict = nn.Sequential(
nn.Dropout(self.dropout),
nn.Linear(self.d_model, self.seg_len)
)
def forward(self, x):
# b:batch_size c:channel_size s:seq_len s:seq_len
# d:d_model w:seg_len n:seg_num_x m:seg_num_y
batch_size = x.size(0)
# normalization and permute b,s,c -> b,c,s
seq_last = x[:, -1:, :].detach()
x = (x - seq_last).permute(0, 2, 1) # b,c,s
# segment and embedding b,c,s -> bc,n,w -> bc,n,d
x = self.valueEmbedding(x.reshape(-1, self.seg_num_x, self.seg_len))
# encoding
_, hn = self.rnn(x) # bc,n,d 1,bc,d
# m,d//2 -> 1,m,d//2 -> c,m,d//2
# c,d//2 -> c,1,d//2 -> c,m,d//2
# c,m,d -> cm,1,d -> bcm, 1, d
pos_emb = torch.cat([
self.pos_emb.unsqueeze(0).repeat(self.enc_in, 1, 1),
self.channel_emb.unsqueeze(1).repeat(1, self.seg_num_y, 1)
], dim=-1).view(-1, 1, self.d_model).repeat(batch_size,1,1)
_, hy = self.rnn(pos_emb, hn.repeat(1, 1, self.seg_num_y).view(1, -1, self.d_model)) # bcm,1,d 1,bcm,d
# 1,bcm,d -> 1,bcm,w -> b,c,s
y = self.predict(hy).view(-1, self.enc_in, self.pred_len)
# permute and denorm
y = y.permute(0, 2, 1) + seq_last
return y
# init
import argparse
parser = argparse.ArgumentParser(description='Model family for Time Series Forecasting')
# forecasting task
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length')
# parser.add_argument('--label_len', type=int, default=0, help='start token length') #fixed
parser.add_argument('--pred_len', type=int, default=96, help='prediction sequence length')
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size') # DLinear with --individual, use this
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
parser.add_argument('--dropout', type=float, default=0.5, help='dropout')
parser.add_argument('--seg_len', type=int, default=48, help='segment length')
# SegRNN
parser.add_argument('--rnn_type', default='gru', help='rnn_type')
parser.add_argument('--dec_way', default='pmf', help='decode way')
parser.add_argument('--win_len', type=int, default=48, help='windows length')
parser.add_argument('--channel_id', type=int, default=1, help='Whether to enable channel position encoding')
# GPU
parser.add_argument('--use_gpu', type=bool, default=False, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
parser.add_argument('--devices', type=str, default='0,1', help='device ids of multile gpus')
args = parser.parse_args()
args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else False
if args.use_gpu and args.use_multi_gpu:
args.devices = args.devices.replace(' ', '')
device_ids = args.devices.split(',')
args.device_ids = [int(id_) for id_ in device_ids]
args.gpu = args.device_ids[0]
model = Model(args).float()
if args.use_multi_gpu and args.use_gpu:
model = nn.DataParallel(model, device_ids=args.device_ids)
batch_x = torch.randn(args.batch_size,args.seq_len,args.enc_in)
# forward
outputs = model(batch_x)
print("输入序列形状: ",batch_x.shape)
print("outputs.shape:",outputs.shape)
Autoformer enc_embedding¶
输入输出:
Bash
输入序列形状[B,S,D]: torch.Size([32, 96, 7])
输入序列时间戳预处理形状[B,S,freq]: torch.Size([32, 96, 4])
outputs.shape[B,S,d_model]: torch.Size([32, 96, 512])
- 代码说明,实现了:
值嵌入、时间嵌入、位置编码
- 没什么好说的,输入都通过命令行参数配置好了
Python
import torch
from torch import nn
import math
# 为了保证不报版本错误
def compared_version(ver1, ver2):
"""
:param ver1
:param ver2
:return: ver1< = >ver2 False/True
"""
list1 = str(ver1).split(".")
list2 = str(ver2).split(".")
for i in range(len(list1)) if len(list1) < len(list2) else range(len(list2)):
if int(list1[i]) == int(list2[i]):
pass
elif int(list1[i]) < int(list2[i]):
return -1
else:
return 1
if len(list1) == len(list2):
return True
elif len(list1) < len(list2):
return False
else:
return True
class TokenEmbedding(nn.Module):
def __init__(self, c_in, d_model):
super(TokenEmbedding, self).__init__()
padding = 1 if compared_version(torch.__version__, '1.5.0') else 2
self.tokenConv = nn.Conv1d(in_channels=c_in, out_channels=d_model,
kernel_size=3, padding=padding, padding_mode='circular', bias=False)
# Conv1d(7, 512, kernel_size=(3,), stride=(1,), padding=(1,), bias=False, padding_mode=circular)
for m in self.modules():
if isinstance(m, nn.Conv1d):
nn.init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='leaky_relu')
def forward(self, x):
# x [B, L, D] → permute → [B, D, L] → 卷积 → [B, d_model, L] → transpose → [B, L, d_model]
x = self.tokenConv(x.permute(0, 2, 1)).transpose(1, 2)
return x
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEmbedding, self).__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
class TemporalEmbedding(nn.Module):
def __init__(self, d_model, embed_type='fixed', freq='h'):
super(TemporalEmbedding, self).__init__()
# 定义各时间单位的可能取值数量
minute_size = 4 # 分钟嵌入表大小(每15分钟一个索引)
hour_size = 24 # 小时嵌入表大小(0-23小时)
weekday_size = 7 # 星期嵌入表大小(星期一到星期日)
day_size = 32 # 日期嵌入表大小(1-31日)
month_size = 13 # 月份嵌入表大小(1-12月,0可能作为填充)
# 根据embed_type选择嵌入类型
Embed = FixedEmbedding if embed_type == 'fixed' else nn.Embedding
# 根据频率创建对应的嵌入层,每个嵌入层输出维度都是d_model
if freq == 't':
self.minute_embed = Embed(minute_size, d_model)
# 创建时间单位的嵌入层
self.hour_embed = Embed(hour_size, d_model)
self.weekday_embed = Embed(weekday_size, d_model)
self.day_embed = Embed(day_size, d_model)
self.month_embed = Embed(month_size, d_model)
def forward(self, x):
# 输入x形状为[B, L, time_features],将其转换为长整型用于嵌入查表
x = x.long()
# 提取每个时间特征并查找对应的嵌入向量
# x[:,:,i]形状为[B,L],通过嵌入后变为[B,L,d_model], [B,L,d_model]或标量0
minute_x = self.minute_embed(x[:, :, 4]) if hasattr(self, 'minute_embed') else 0.
hour_x = self.hour_embed(x[:, :, 3]) # [B,L,d_model]
weekday_x = self.weekday_embed(x[:, :, 2]) # [B,L,d_model]
day_x = self.day_embed(x[:, :, 1]) # [B,L,d_model]
month_x = self.month_embed(x[:, :, 0]) # [B,L,d_model]
# 将所有时间特征的嵌入向量相加,形成最终的时间嵌入
# 每个时间特征输出形状为[B,L,d_model],相加后形状不变
return hour_x + weekday_x + day_x + month_x + minute_x
class TimeFeatureEmbedding(nn.Module):
def __init__(self, d_model, embed_type='timeF', freq='h'):
super(TimeFeatureEmbedding, self).__init__()
# freq_map定义不同数据频率下使用的时间特征维度
freq_map = {'h': 4, 't': 5, 's': 6, 'm': 1, 'a': 1, 'w': 2, 'd': 3, 'b': 3}
d_inp = freq_map[freq] # 根据频率确定输入维度
self.embed = nn.Linear(d_inp, d_model, bias=False) # 创建无偏置的线性层将d_inp维度映射到d_model维度
def forward(self, x):
# 输入x形状: [B, L, d_inp] - B是批次大小, L是序列长度, d_inp是时间特征数量
# 线性变换后输出形状: [B, L, d_model]
return self.embed(x)
class DataEmbedding_wo_pos(nn.Module):
def __init__(self, c_in, d_model, embed_type='fixed', freq='h', dropout=0.1):
super(DataEmbedding_wo_pos, self).__init__()
self.value_embedding = TokenEmbedding(c_in=c_in, d_model=d_model)
self.position_embedding = PositionalEmbedding(d_model=d_model)
self.temporal_embedding = TemporalEmbedding(d_model=d_model, embed_type=embed_type,
freq=freq) if embed_type != 'timeF' else TimeFeatureEmbedding(
d_model=d_model, embed_type=embed_type, freq=freq)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, x_mark):
# x [B, L, D] → permute → [B, D, L] → 卷积 → [B, d_model, L] → transpose → [B, L, d_model]
# x_mark [B, L, d_inp] → 线性层变换(时间特征整体映射) → [B, L, d_model]
# x_mark [B, L, time_features] → 提取时间特征并查表 → 分别嵌入 (月/日/星期/小时/分钟) → 每个时间特征 [B, L, d_model] → 相加 → [B, L, d_model]
# [B, L, d_model] + [B, L, d_model] → [B, L, d_model]
x = self.value_embedding(x) + self.temporal_embedding(x_mark) + self.position_embedding(x)
return self.dropout(x)
import argparse
parser = argparse.ArgumentParser(description='Model family for Time Series Forecasting')
#默认使用 TimeFeatureEmbedding 嵌入
parser.add_argument('--embed', type=str, default='timeF',help='time features encoding, options:[timeF, fixed, learned]')
parser.add_argument('--freq', type=str, default='h',
help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
parser.add_argument('--dropout', type=float, default=0.5, help='dropout')
# 时序标配 BSD BPD d_model D这里记作 enc_in 有的是 pred_len + label_len
parser.add_argument('--batch_size', type=int, default=32, help='batch size of train input data')
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length')
parser.add_argument('--label_len', type=int, default=0, help='start token length') #fixed
parser.add_argument('--pred_len', type=int, default=96, help='prediction sequence length')
parser.add_argument('--enc_in', type=int, default=7, help='encoder input size') # DLinear with --individual, use this
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
args = parser.parse_args()
enc_embedding = DataEmbedding_wo_pos(args.enc_in, args.d_model, args.embed, args.freq,args.dropout)
# enc
# 编码器输入嵌入,将原始时间序列特征转换为模型内部表示
# 形状变化:x_enc[B, L, D] -> enc_out[B, L, d_model]
x_enc = torch.randn(args.batch_size,args.seq_len,args.enc_in)
x_mark_enc = torch.randn(args.batch_size,args.seq_len,4)
#因为是小时,数据封装的时候会计算 offsets.Hour: [HourOfDay, DayOfWeek, DayOfMonth, DayOfYear]
enc_out = enc_embedding(x_enc, x_mark_enc)
print("输入序列形状[B,S,D]: ",x_enc.shape)
print("输入序列时间戳预处理形状[B,S,freq]: ",x_mark_enc.shape)
print("outputs.shape[B,S,d_model]:",enc_out.shape)
UNetTSF¶
输入&输出
说明: