简介
SENet只考虑了通道之间的相关性, 而忽略了位置之间的重要性,而在视觉任务中通常空间结构是最重要的,因此本文将通道注意力和空间注意力进行了串联,本文的结构是通道注意力和空间注意力的串联
问题
- 第一 作者的空间注意力是如何实现的
- 第二 作者提到的通道注意力有没有改进
- 第三这两者是如何串联的
模型架构
首先看一下CBAM的模型架构
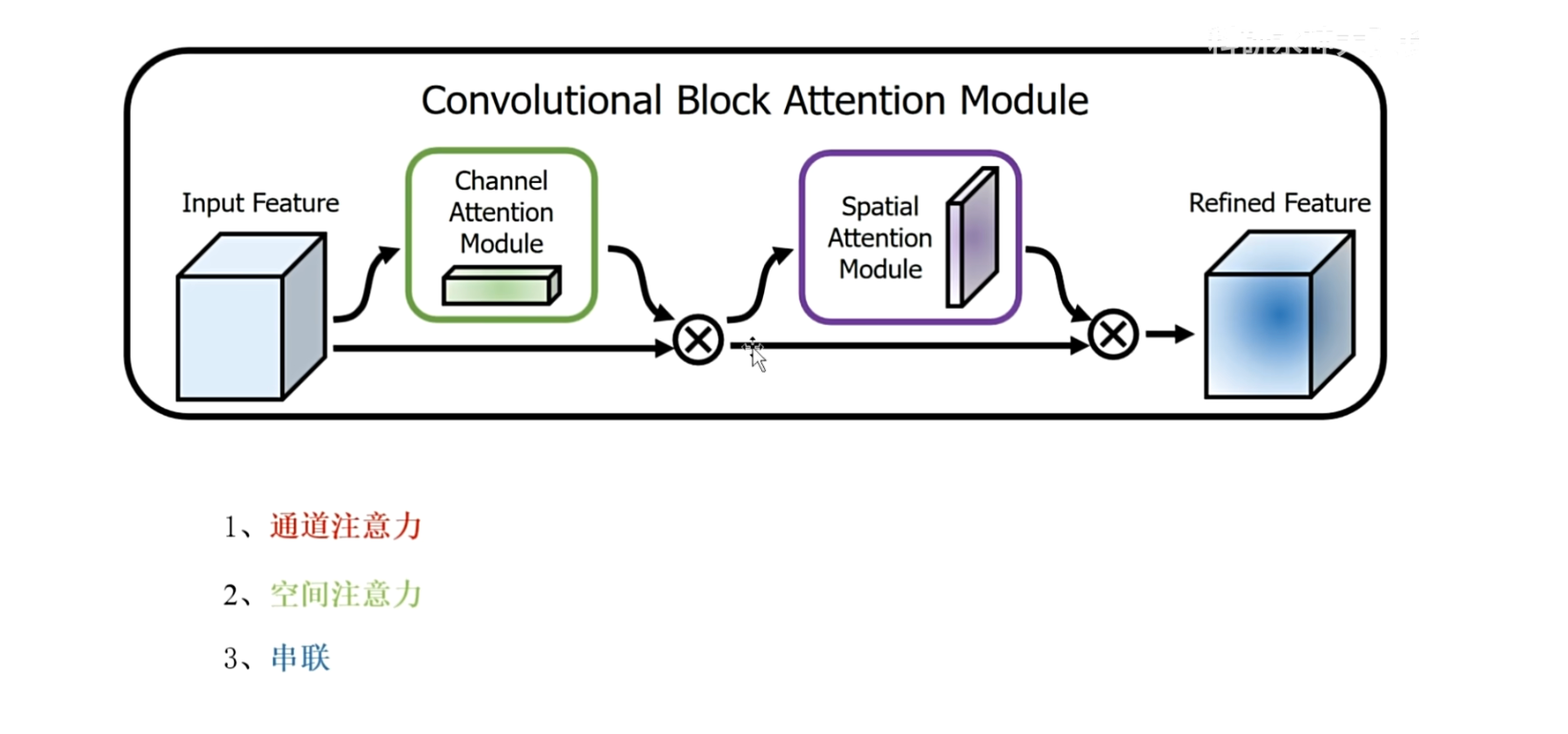
输入特征,首先通过一个通道注意力模块得到权重,然后进行相乘来调整输入特征,每个通道的重要性,然后更新后的特征通过空间注意力模块得到权重,对应的就是调整更新后特征的每个空间像素上的权重
通道注意力
计算流程图
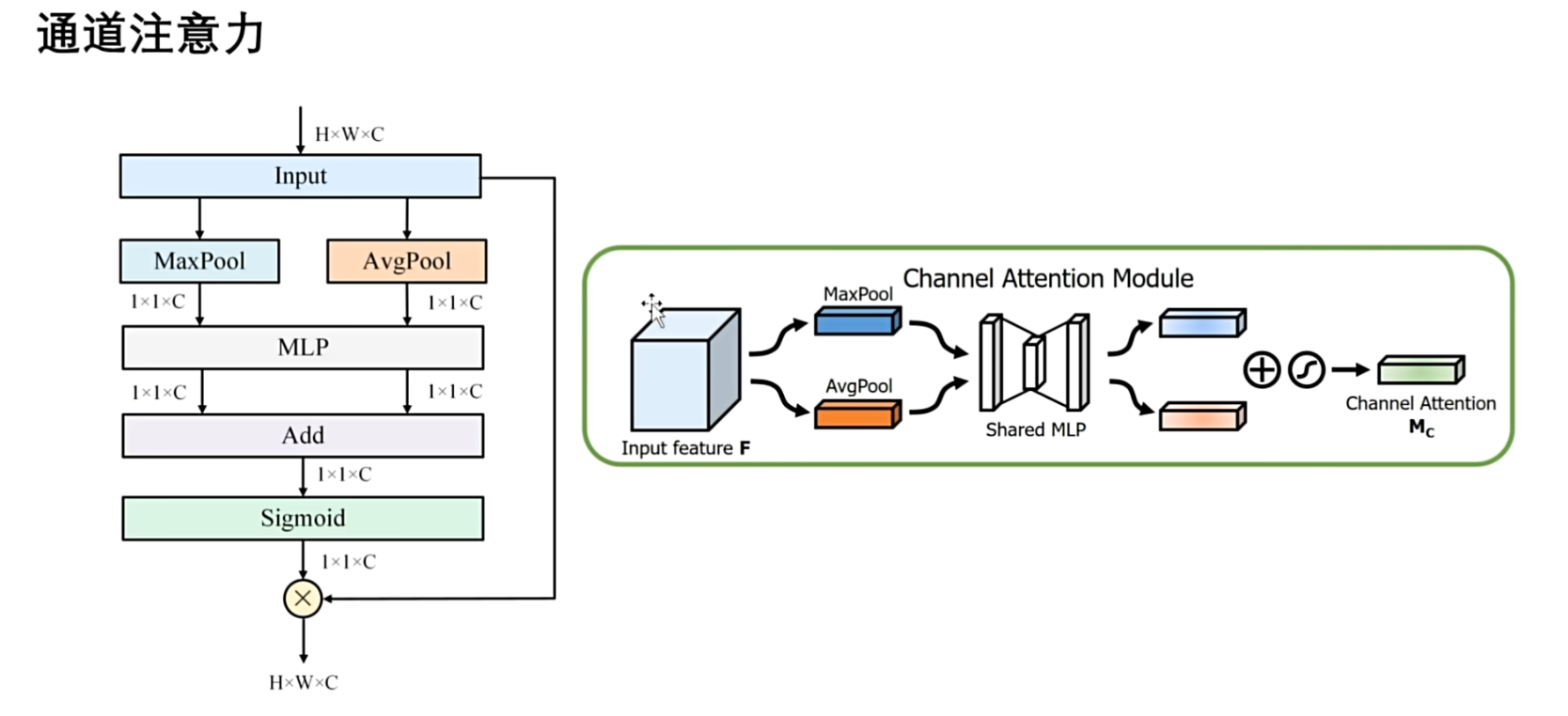
输入特征,通过最大池化和平均池化两个池化层,来提取不同种类的全局信息,得到的都是 $1×1×C$ 的一个通道描述符表示 ,最大池化提取的是最重要的特征,肯定会丢失一些次重要的信息,平均值化就可以弥补细节,生成的都是 $1×1×C$ 的通道描述符,两个全局特征表示,通过共享参数的全连接层,这样能够减少参数数量来降低模型的复杂度,从而来提高模型的训练速度,然后将两个输出直接进行相加,融合最大和平均特征表示,最后通过 Sigmoid 函数来生成通道注意力权重( $1×1×C$ ),并与输入的特征进行相乘,得到输出后的特征,紧接着更新后的特征,输入到空间注意力模块
空间注意力
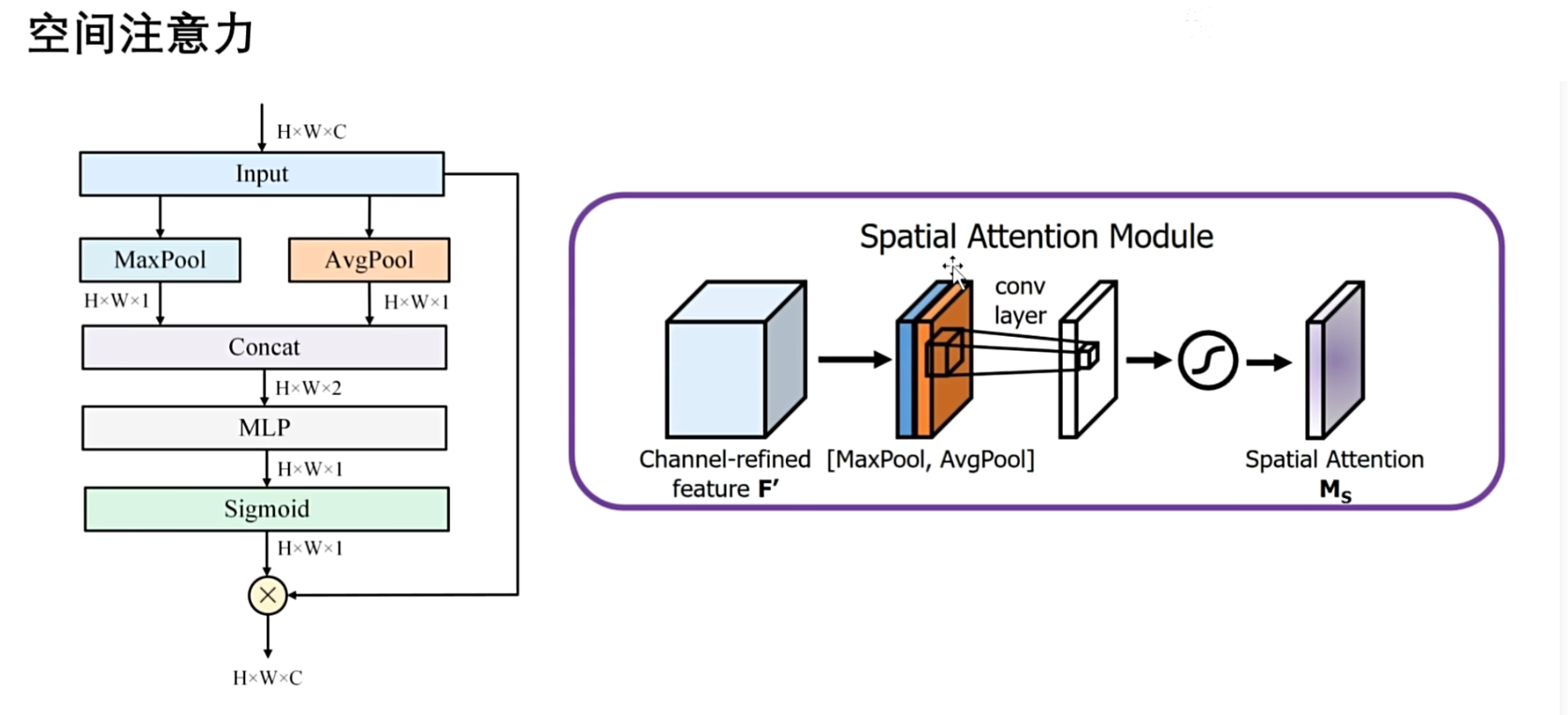
通道注意力是通过压缩空间特征来得到通道描述符,在这里是反过来
作者通过压缩通道特征来得到空间描述符,是通道方向上,执行最大池化和平均池化,得到通道维度上的全局特征表示,shape 都是 $H × W × 1$ , 然后将它们进行拼接,得到 $H × W × 2$ 的矩阵,然后再通过MLP融合这两种全局特征,最大和平均特征, 将其重新映射到 一维 $H × W × 1$ , 这里也可以直接进行相加,然后通过MLP,这样的话就再进行拼接和降维了,最后通过 Sigmoid 函数,生成空间注意力权重,并与输入特征进行相乘
回答问题
第一 作者的空间注意力是如何实现的
作者只是将通道注意力的思想,迁移到了空间上,通过压缩通道上的特征来生成空间注意力
第二通道注意力有没有改进
在通道注意力上,作者仅仅是增加了一个最大池化层,然后使用的是共享全连接层,没有使用全连接层来降维再升维
第三两者是如何串联的
就是简单的一个串联操作
回到老祖SENet
回顾之前的创新切入点,把CBAM套路进来,作者是在压缩部分来做的创新,第一是如何压缩,使用的是平均池化和最大池化,第二是在压缩层面上做了创新,在不仅在通道上做了创新,在空间上也做了创新,空间和通道上都做了
二次创新
还是三个问题:
- 第一个是空间注意力的实现
- 第二个是通道注意力的改进
- 第三个是如何串联
通道注意力的改进方式已经说过啦,重点放在串联方式上,作者使用的是简单的串联操作,可以变为一个并联,两个分支,分别保留通道上和空间上的权重,然后加权,最后两部分直接相加
第三种融合操作,就是不孤立的分析通道和空间注意力,而是把通道注意力融合到空间注意力中,或者是把空间注意力融合到通道注意力中,两部分来联合建模直接进行交互,得到更全面的特征,能够在一定程度上提升模型的性能.
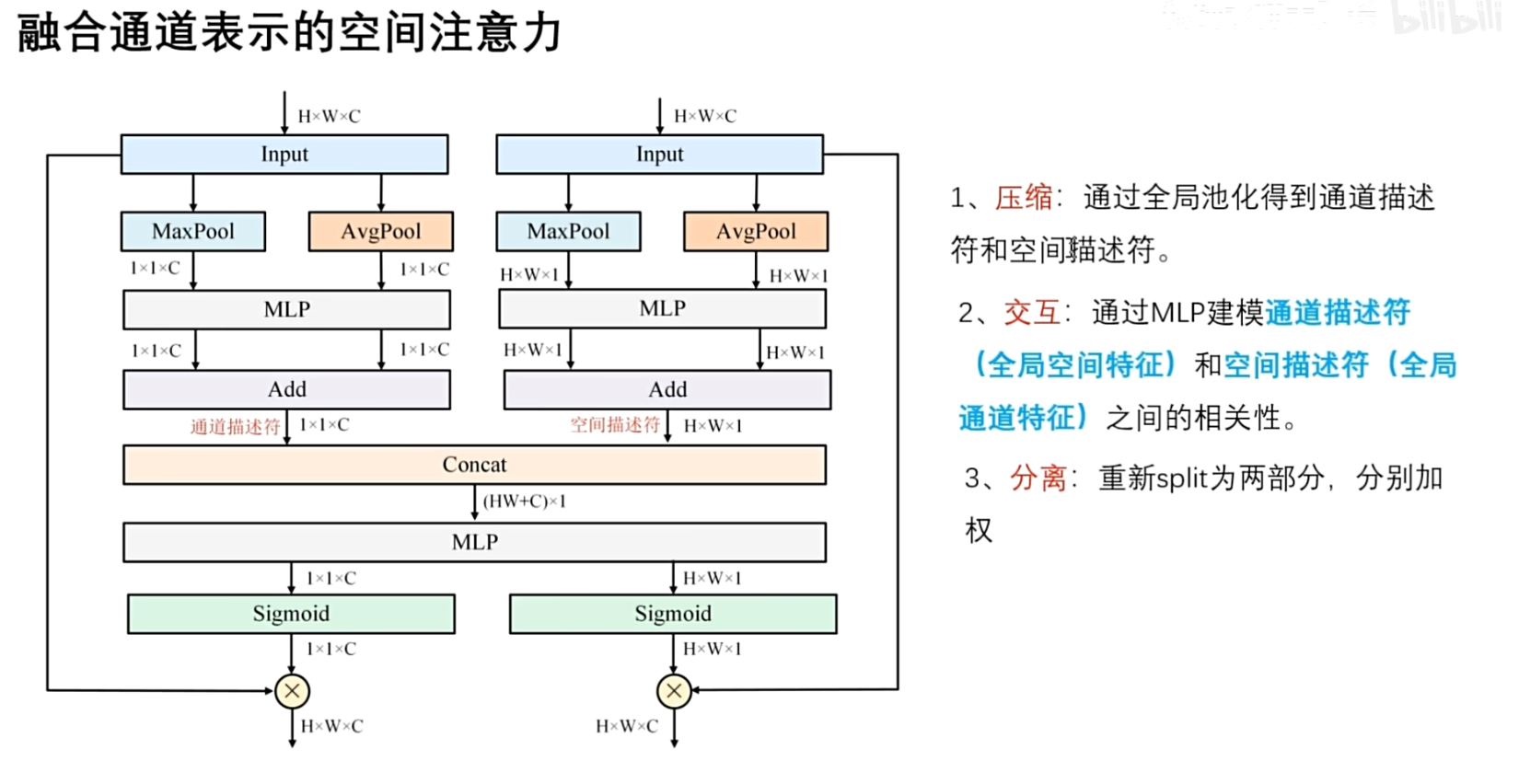
融合通道表示的空间注意力,也分为三个部分,第一是压缩,第二部分是交互,第三是分离.
在压缩部分,可以看到通道注意力和空间注意力都是通过一个最大池化和平均池化,来分别生成通道描述符和空间描述符表示
第二部分交互部分,将通道描述符和空间描述符进行拼接,先用concat进行拼接,拼接成这个 $(HW+C)\times 1$ 的向量 , 然后通过MLP来建模相关性.
讨论这里的意义:
- 通道描述符,聚合全局的空间特征
- 空间描述符,聚合全局的通道特征
关于空间特征和通道特征之间有关系吗?
不知道有没有,但我相信它有,所以可以就把它定义为一种潜在的依赖关系,所以就必须建模它们之间的一个相关性,这里用了一个简单的MLP,用卷积或者多尺度卷积也可以
第三部分分离,交互完之后,将它们重新进行分割为两部分,$1×1×C$ 和 $H×W×1$ ,恢复为原有的shape,然后再与对应的输入进行相乘,通过 Sigmoid 函数得到权重,再与对应的输入进行相乘操作,又得到了两个输出,可以相加,得到总的输出,也可以把这两部分输出,分别输入到下一个模块.