CVPR2021
坐标注意力
通道注意力的变体
简介
通道注意力是有效的,但是2D池化会丢失位置信息,而位置信息对于生成空间注意力映射是非常重要的
动机
SENet把$H×W$这么大的空间池化成$1×1$大小的空间,除了有一个1×1的小格子什么也看不到了,意味着信息丢失太多
本文提出了一种将位置信息嵌入到通道注意力的新注意力方法:坐标注意力
不同于SENet通过2D池化压缩空间特征为通道描述符向量坐标,坐标注意力将通道注意力分解为两个1D 编码的过程,两个过程分别沿着两个空间方向聚合为两个独立的方向感知特征图
把空间H×W这个层面进行再次分解,分为了H层面和W层面分别池化,美曰其名方向感知特征图
这两个嵌入特定方向信息的特征图,分别被编码为两个注意力图,每一个都捕捉了输入特征沿着一个空间方向的长程依赖
意思就是说,例如在H方向上进行池化,将长度为H的向量池化为一个长度为1的向量,那么这个长度为1的向量,就具有了H方向上的全局信息,也就是作者提到的长程依赖
计算流程
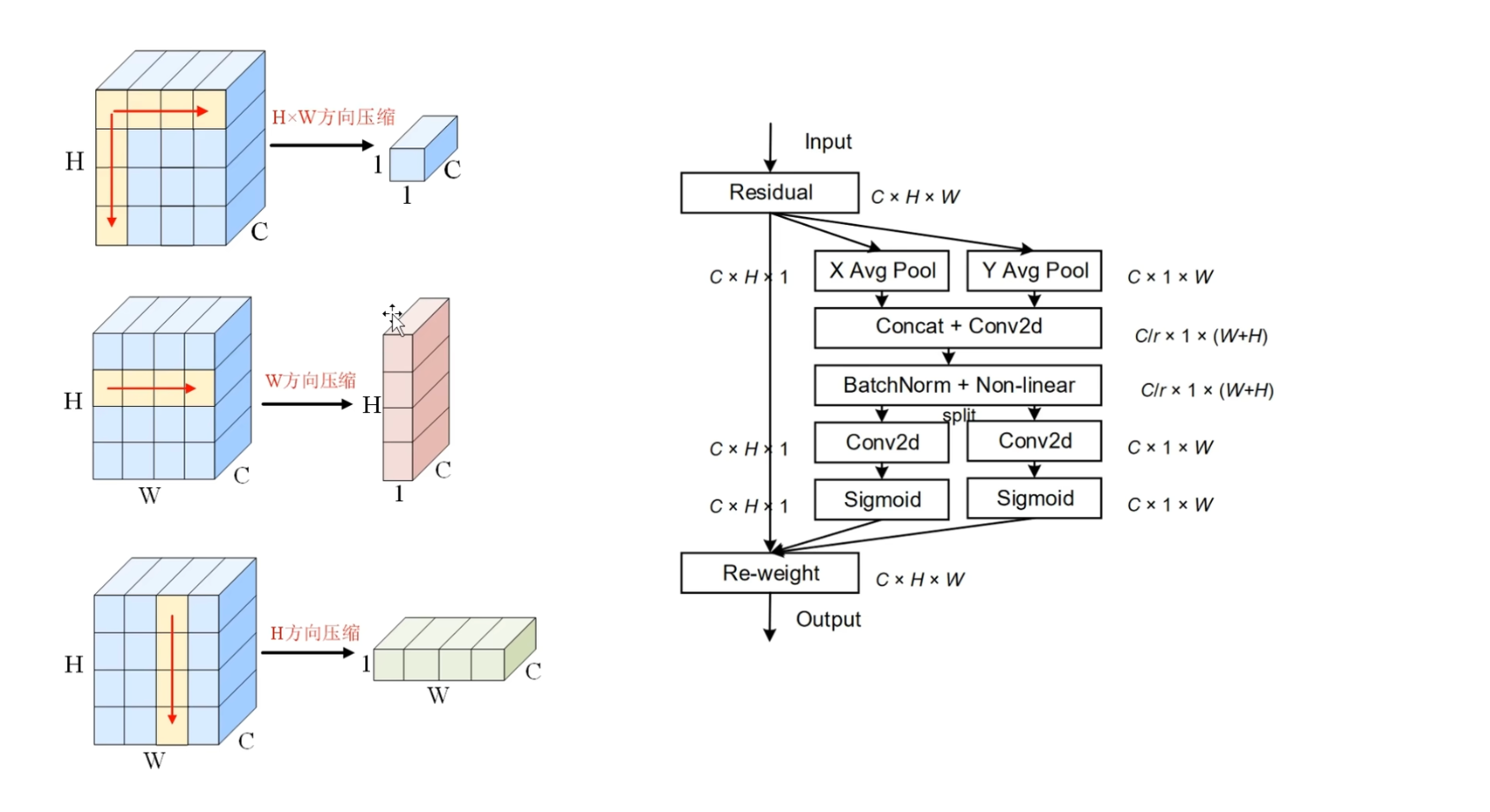
左边的压缩图 可以看到2D池化W方向和H方向池化分别是什么样子的,输入输出的shape是什么样子的
右图坐标注意力的计算流程图
- 首先输入的是一个$C×H×W$的特征图
- 然后,分别在X方向和Y方向上进行池化操作,X和Y方向对应的就是W方向和H方向,然后分别得到 $C×H×1$ 和 $C×1×W $ 的矩阵,然后将它们在空间方向上进行拼接,得到的矩阵就是 $C×1×(H+W)$
- 这里作者通过一个卷积,建模H方向上的全局特征和W方向上的全局特征之间的通道依赖性,并通过
降维来提高计算效率 - 后面的就是接 BatchNorm 和 ReLU 激活函数
- 作者将 $\frac{C}{r}$×1×(H×W) 拆分为两个向量 $\frac{C}{r} ×1 ×H$ 和 $\frac{C}{r} ×1×W$ ,然后再分别通过两个卷积层,恢复到与输入相同的通道数 $C$ , $C×H×1$ 和 $C×1×W$ ,最后也是常规操作,分别通过Sigmoid函数生成权重表示,然后来调整输入表示
象形图
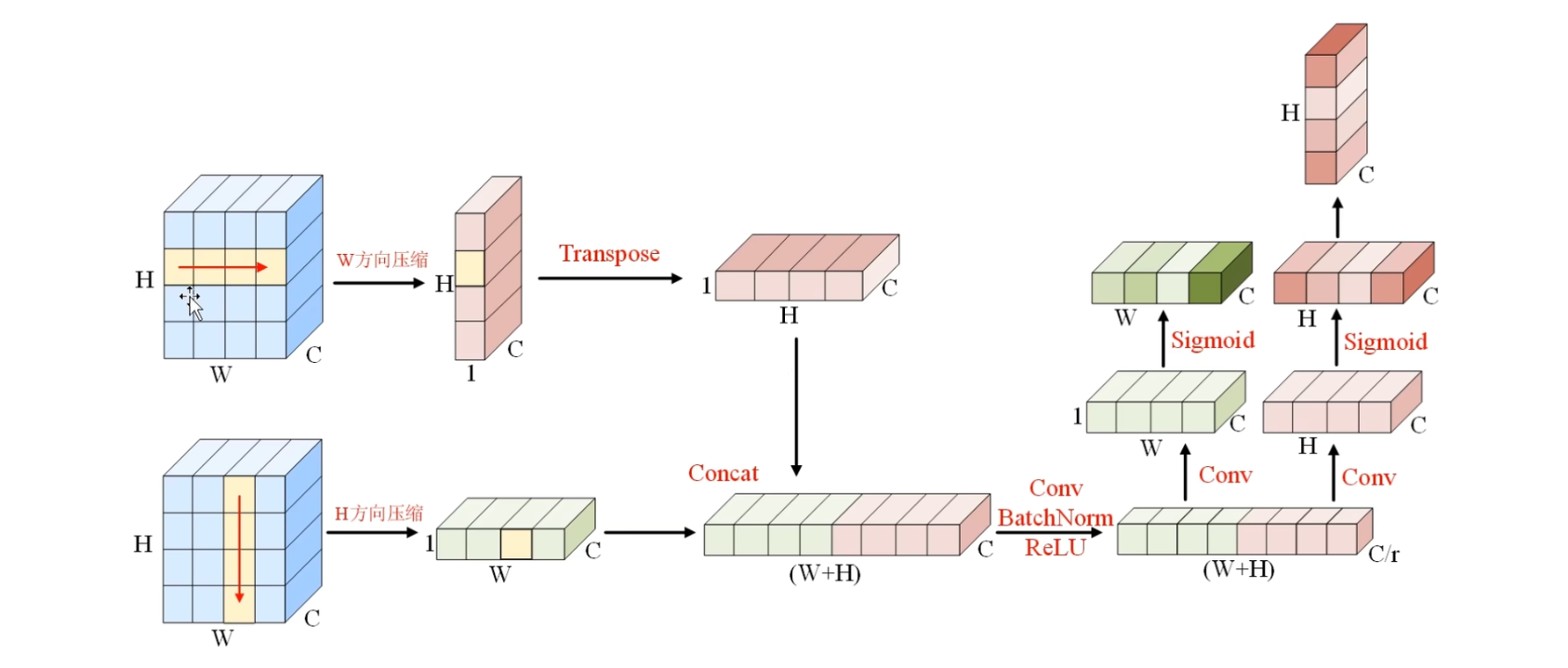
如图,沿着W方向,也就是水平方向$ \rightarrow C×H×1$
还有垂直方向,也就是H方向上进行压缩 $ \rightarrow C×W×1$
以这个W方向上的压缩为例,
① 捕捉了W方向上的长距离的依赖性,不管图片有多大,都将长度为W的信息,压缩到一个小格子之内,
② 其次 $C×H×1$ 的矩阵,高度没有变化依然是H,也就是依然保留着垂直方向上的位置信息,例如当模型认为小格子内的特征更重要的时候,也知道它是在垂直方向上的,第二个格内保留了位置信息
在H方向上的压缩 也是同样的道理,
① 首先捕捉H方向上的长距离依赖性,将高度为H的信息 压缩到长度为1的一个小格子之内,
②其次,使模型能够意识到重要的特征,比如处于水平方向的第三个小格子内
使得这两个层面都具有了全局感受和相应的位置信息,既拥有了X坐标还拥有了Y坐标
为了利用这两个维度的信息,作者进行了第二次变换称之为坐标注意力生成,简单来讲就是将它们拼接到一起,学习通道之间的关系
坐标注意力生成
首先将 $1×H×C $ 的矩阵进行翻转, 翻转完之后,将绿色的和粉色的矩阵拼接到一块儿,注意是在空间方向上拼接在一块儿,也就是H和W方向上,
然后,通过一个1×1的卷积层来学习所有通道之间的相关性,顺便把这个通道降低到 $\frac{C}{r}$ ,可以提高计算效率,降维后的特征,就同时编码了空间垂直方向和空间水平方向上的特征,
当编码完成之后,作者重新将它们进行分割,分割为两个矩阵,长度分别为W和H,并分别通过卷积层来恢复C的通道,然后再分别通过sigmoid函数来生成对应的权重表示
那么根据H方向上的权重和W方向上的权重,模型就能够准确定位图像中重要的区域
对比 SENet
SENet 生成$1×1×C$的通道描述符,对$H×W$空间层面上的所有像素点,都用一个向量来调整权重,而坐标注意力生成两个权重 $C×H×1 $和 $C×1×W $ ,来分别调整H方向和W方向上的重要性,使得空间层面上的每个像素点都有属于自己的权重,直观上更加合理,小小的做法,大大的思想