基于细节增强卷积和内容引导注意力的单图像去雾
TIP2024
2023年1月份向TIP提交,2024年1月份被接受,历时大概一年
简介
先介绍一下任务是什么: 单幅图像去雾是一个具有挑战性的问题,从观察到的模糊图像中估计潜在的无模糊图像
在融合深层和浅层特征的时候,由于感受野不同,浅层特征中编码的信息与深层特征中编码的信息有很大不同
浅层特征,通常来讲就是靠近输入端的卷积层所提取的特征,通常具有较小的感受野,也因此只能关注图像中的局部信息,比如说边缘纹理和颜色等低级特征, 这些特征往往与局部细节密切相关,对图像的基本结构和边缘信息具有很好的捕捉能力
深层特征是指随着网络层数的加深,感受野逐渐增加,这个时候所提取的深层特征就包含了更大的图像区域,简单来说,深层特征更关注整体的结构
举例
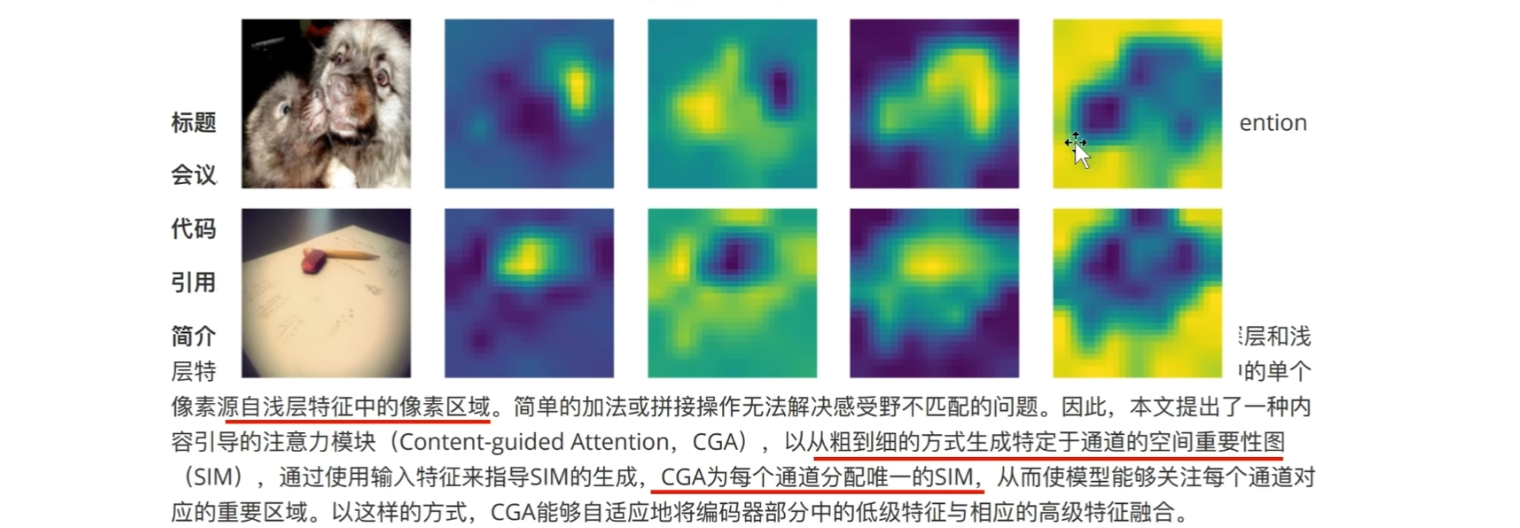
这是一个连续四个卷积层的可视化图片,可以看到在浅层的时候,更关注一些局部细节,随着层数的加深,关注的区域范围也是越来越大,接着看深层特征中的单个像素,源自浅层特征中的像素区域
简单的加法或者拼接操作无法解决感受野不匹配的问题
本文中的一个核心挑战: 感受野不匹配
首先我们要理解这个现象
浅层到深层是一个逐步递进的过程,深层特征中的一个像素值,实际上是浅层特征图,多个像素信息的汇总,是一个包含的关系
感受野不匹配
加法拼接都无法解决它
举例

如图所示: 在浅层特征中呀,每个像素都代表该区域内的具体细节,例如树叶的颜色,局部纹理等,在它对应的深层次的特征,一个像素就代表了图像中这么较大的区域,例如这一大片树叶
前者更关注具体细节,后者关注全局
如果将它们简单地进行相加或者拼接,并不能有效的将这两种信息整合到一起,相反浅层的细节可能会被深层信息淹没,或者深层的全局信息,无法得到充分的表达
为了解决感受野不匹配的问题,本文提出了内容引导的注意力模块,以从粗到细的方式生成特定于通道的空间重要性图SIM
通过使用输入特征来指导SIM的生成, CGA为每个通道分配唯一的SIM,从而使模型能够关注每个通道对应的重要区域
以这样的方式,CGA能够自适应的将编码器部分中的低级特征与相应的高级特征融合
方法
从方法中挖掘作者的具体想法和思路
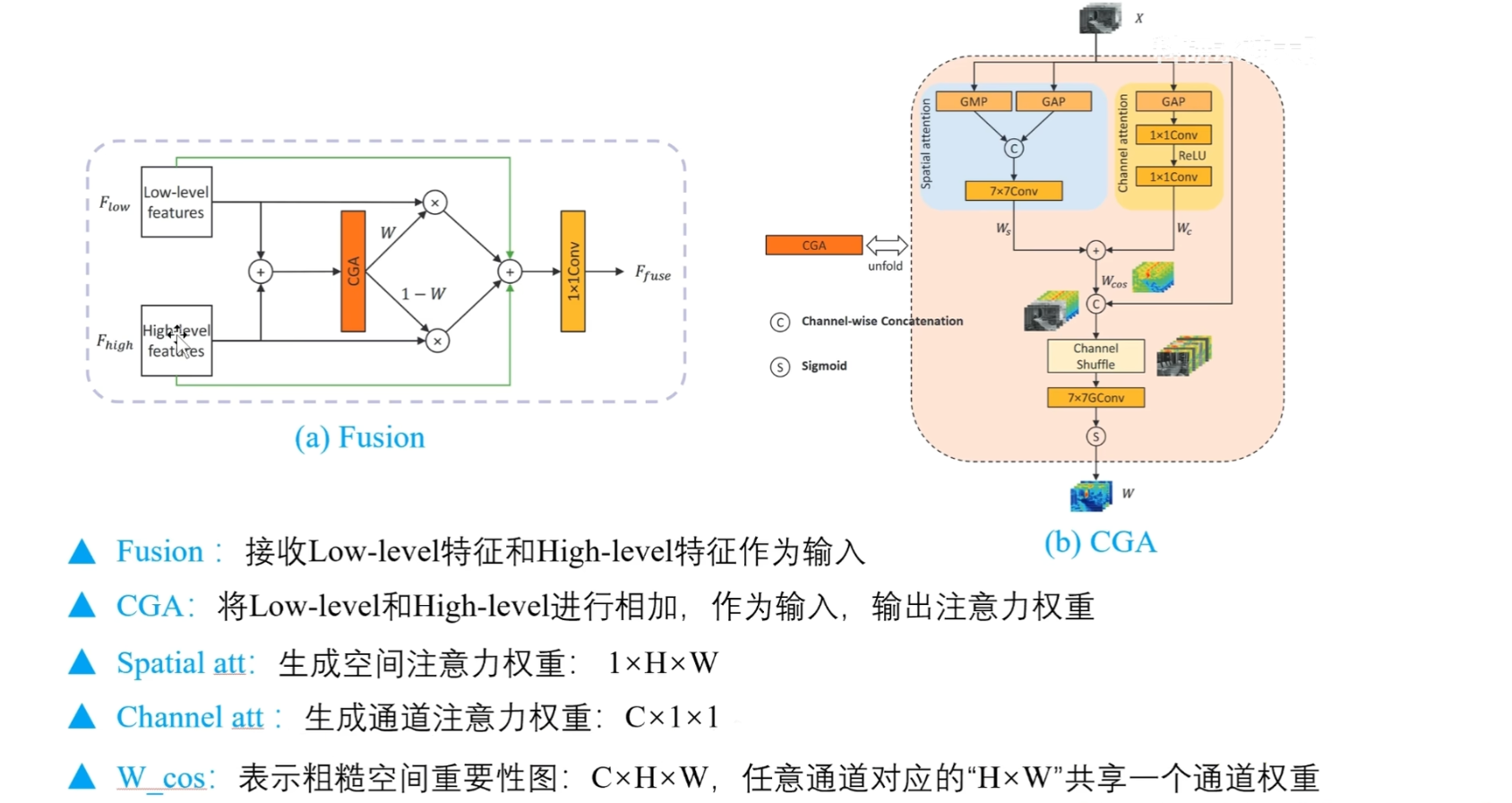
左图是融合模块,给定低级和高层次的特征,然后两者进行相加,汇入到CGA模块,CGA模块输出注意力权重,用于对低层特征和高层特征进行加权求和
右图是本文中的重要创新点,CGA模块: 内容引导的注意力
首先给定低层和深层特征相加后的表示,
$X$ 左分支是空间注意力 ,右分支是一个通道注意力(做法虽然简单,但提点)
空间注意力在通道方向上分别执行全局平均池化(GAP)和全局最大池化(GMP),然后拼接,并且通过卷积来进行降维,得到空间注意力权重
空间注意力权重,会捕捉每个位置或者像素的重要性,但是并不关注特定通道内的信息差异,也就是说每个通道共享空间权重
通道注意力在空间方向上,执行全局平均池化,然后通过两层的全连接层
这里用卷积层(1×1的卷积)替代(MLP)来建模通道上的一个相关性,得到通道注意力权重,通道注意力权重,为每个通道只分配一个权重值,但是并没有考虑图像在空间上的细节差异,也就是说空间上的所有像素点,共享一个通道权重
然后空间注意力权重和通道注意力权重进行相加,虽然说它们的shape完全不同,但是在这里可以用到广播机制是能够正常相加的
融合后的注意力权重,作者把它叫做粗糙的空间重要性图
为什么这么说呢?
因为这种融合只是将空间和通道两个维度的信息粗略的结合,它并没有细化到每个通道在不同位置上的具体重要性
目前的情况是,每个通道在所有位置上都是一个作用并没有产生区分
所以接下来,粗糙的空间重要性图和输入的特征进行拼接,在通道方向上进行拼接,然后在通道方向上又进行一个打乱,进行一次洗牌操作,然后用一个7×7的卷积,将通道从2C降维到C,最后通过Sigmoid函数来生成最终的权重
作者把这两个联系的操作叫做内容引导的注意力
简单来说就是使用这个输入特征来调整中间的粗糙的空间重要性图,类似于为这个粗糙的空间重要性图添加一个先验知识,从而让模型根据输入图像的具体内容自适应的关注每个通道在不同位置上的重要区域,从而生成更加精准的空间重要性图
拓展
大部分人到粗糙的空间注意力图就已经结束了,但是作者在这个基础上,挖掘出了更深层次的挑战,这个粗糙的空间注意力图,能提供给我们什么信息,它在哪方面表现还不够好,我们应当如何去弥补这一缺陷,那么从这几个疑问出发,并且加以拓展
作者提出了一个新的问题,也就是浅层特征和深层特征在融合的时候,所遇到的感受野不匹配的问题,解决这个问题的核心操作,就是把输入特征作为先验知识来添加进来,很简单的做法,但是内容深度却足以使它发表在CCFA(TIP期刊)上面
更重要: 在精讲算法的时候,讲简介花费的时间最多,讲的最细,因为简介中它包含挑战,还有动机都是论文中最重要的部分,方法总是千篇一律,大同小异,模块A加B可能仅仅支撑中三区,但是如果在问题中升华,找到一些有趣的问题(怎么找-.-)