Nips2022
简介
自注意力机制是建模长程交互的先进方法,但涉及到大量的交互和聚合操作,并且具有二次方的计算复杂度
🚩 (点明动机) 自注意力机制的复杂度太高
☑️ 什么是交互,什么是聚合
作者还提到了交互和聚合,首先回顾一下注意力机制的两个核心步骤
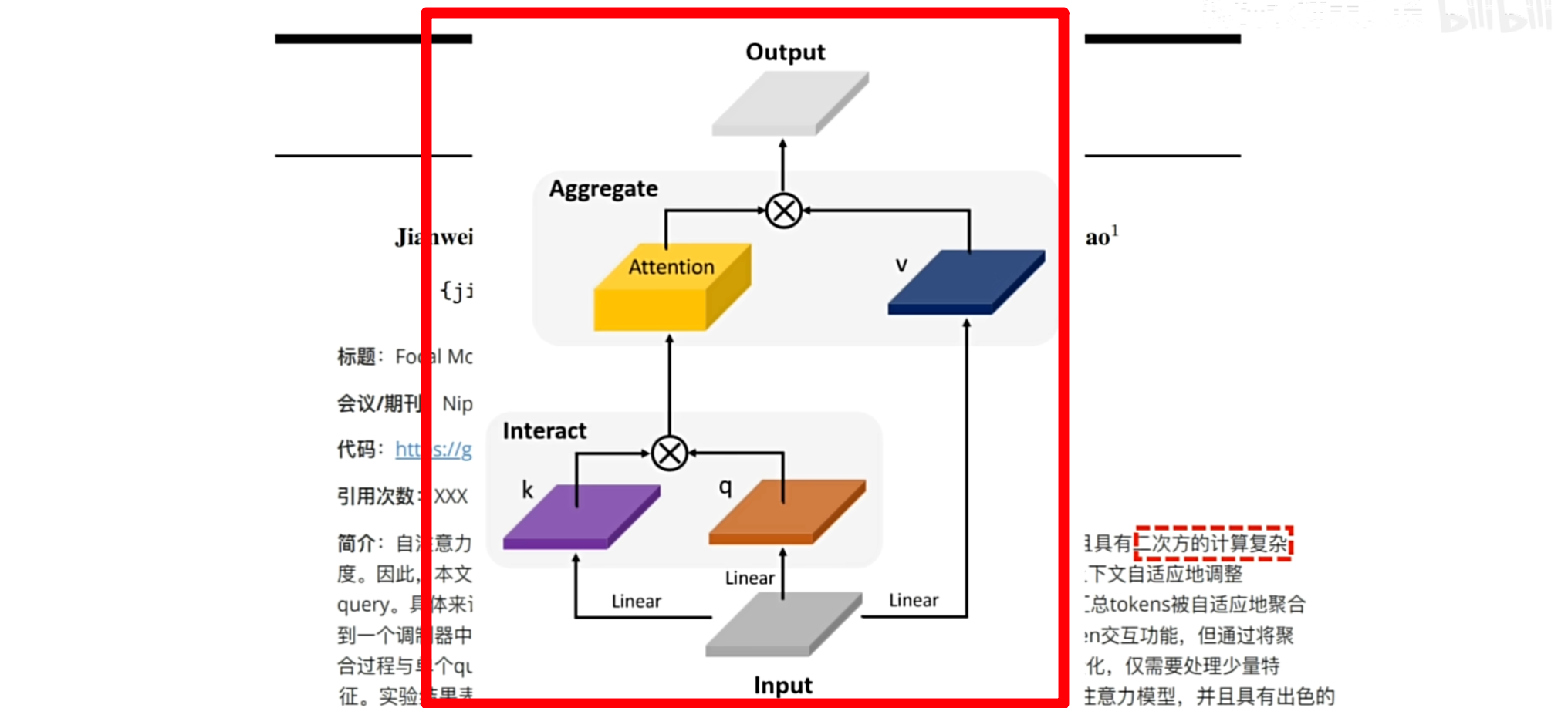
①先计算Q和K的点积得到注意力权重
②通过这个权重对value矩阵进行加权
那么很显然Q和K相乘的过程,就是作者提到的交互
对value矩阵进行加权,就是聚合操作
因此本文提出了一种新的方法,首先围绕每个query聚集上下文,然后用聚集的上下文自适应的调整query
具体来说,简单地应用深度卷积来生成不同粒度级别的汇总tokens
汇总 tokens被自适应的聚合到一个调制器中, tokens被自适应的聚合到一个调制器中
这段话涉及到了三个操作
① 第一生成不同力度级别的汇总tokens,实际也就是生成多尺度信息
②第二汇总tokens被自适应的聚合,也就是多尺度信息的融合,融合后的表示,作者称之为调制器
③第三,该调制器最终被注入到query中, 很显然就是在做交互
从字面意思来理解,注入可能是相加相乘或者拼接都有可能,这种做法仍然保留了基于输入的token交互功能
但通过将聚合过程与单个query token解耦,显著简化计算过程,从而使得交互过程变得更加轻量化仅需要处理少量的特征
实验结果表明实现了最佳性能
为什么作者会提出这样一种方法
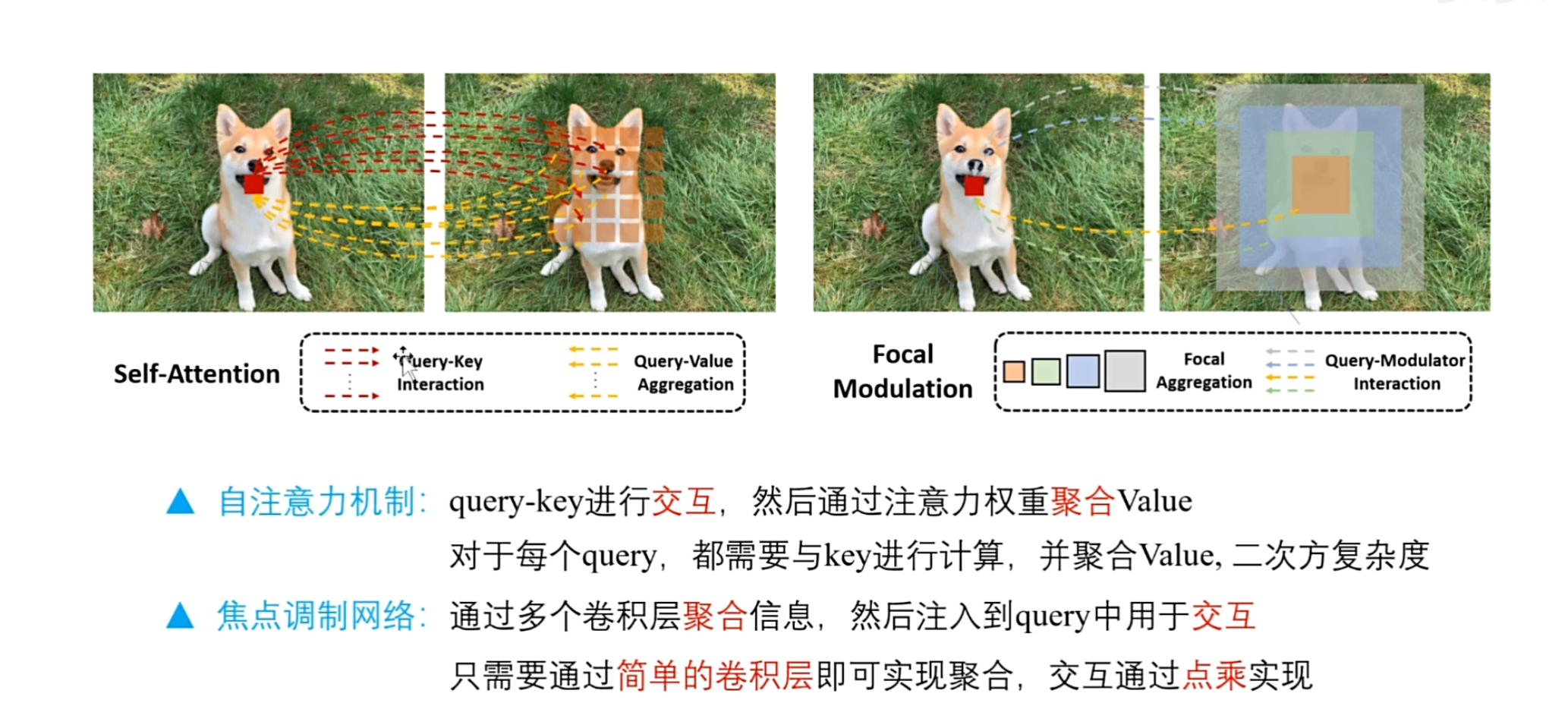
首先来看自注意力机制,假设红色像素块是query,首先和其他所有的像素块的特征做向量乘法,这样在每一个位置就可以得到注意力权重,然后将得到的权重,与对应像素块本身的特征进行相乘,就得到了加权后的特征,最后将所有加权后的特征进行求和,就是更新后的像素块的新特征
(左图),红色细线和黄色虚线就分别表示交互和聚合
在这个自注意力机制中,对于每一个query都需要和其他所有的像素进行向量乘法,然后再加权
如果query像素足够多的话,计算是非常缓慢的,具有二次方的计算复杂度,这也是transformer模型的一个局限性
(右图)因此呢作者提出了一种新的方法,首先在这个图片上执行多个连续的具有不同卷积核大小的卷积层,就可以得到多个具有不同尺度的上下文表示
(看右图) 在这里还是以红色query表示为例,它处于中性位置
这个橙色,绿色,蓝色,灰色,就是这个红色query在不同尺度下对应的局部上下文特征,作者也把它们称之为焦点聚合操作,只不过焦点大小是有区别的,然后将生成的具有不同尺度的上下文,依次注入到红色的query中,用于更新红色query的新信息
很显然作者提出的新方法,是先通过多个卷积层来聚合信息,然后再与query做交互和自注意力,是一个相反的顺序. 相比之下,作者提出的方法更加轻量级,只需要通过简单的卷积层即可实现聚合,交互是通过点乘来实现的
模型图
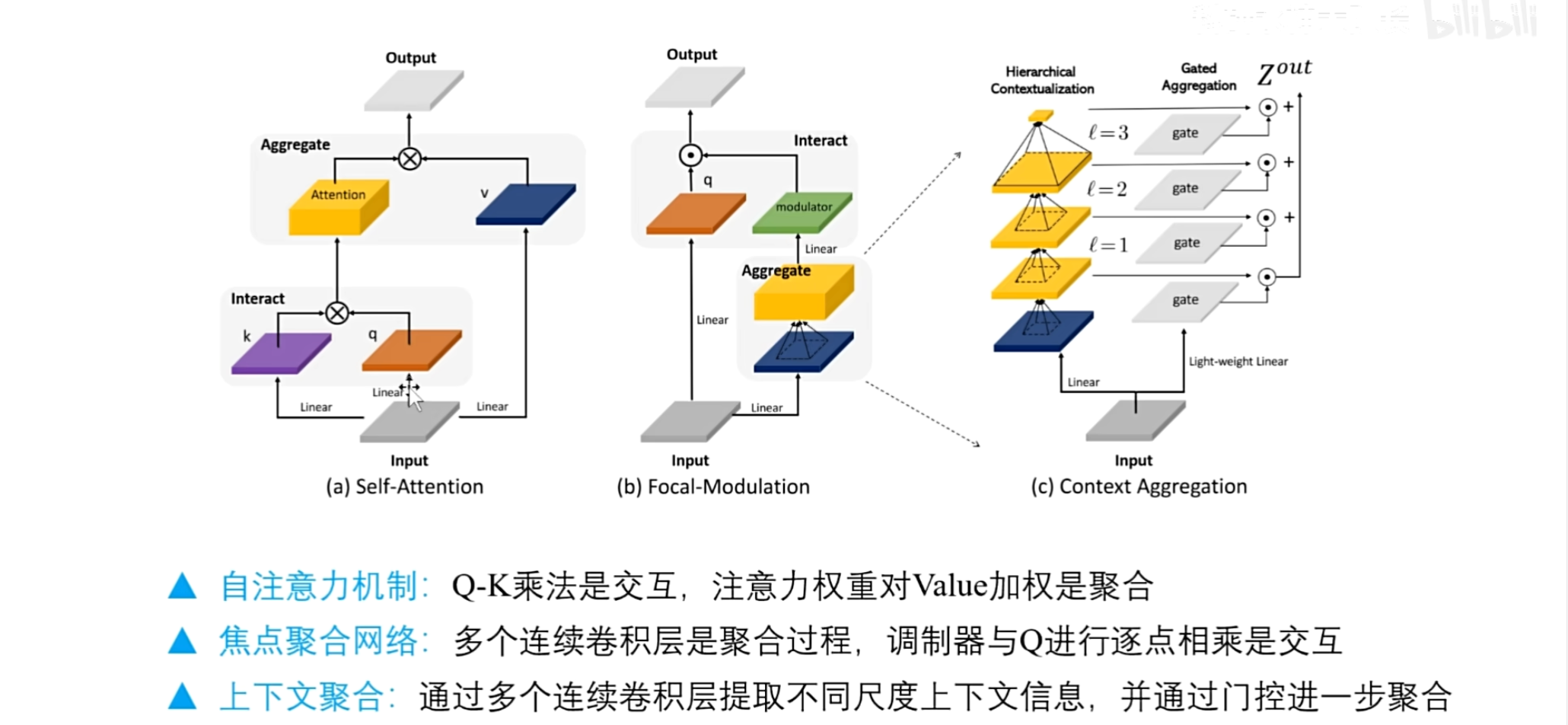
该模型图有三部分,作者标注的很清楚
图(a) 对于自注意力,Q和K进行矩阵乘法是交互 ,注意力权重对value加权是聚合
图(b) 对于作者提出的焦点调制网络,通过多个连续的卷积层,实现信息的聚合
并进一步通过线性层来生成调制器,调制器与Q矩阵直接进行点乘作为交互操作,这是上下文信息聚合模块
图(c)
上下文信息聚合模块
首先,作者通过一个线性层进行线性变换,然后连续执行三个卷积层,生成三个不同尺度的上下文信息表示,在最后一层直接通过一个全局平均池化获得全局信息表示
然后作者在这里还利用输入,为每一层都生成了权重诶
权重怎么生成?
利用线性层,最后通过权重,对这几个不同尺度的信息,进行加权求和再生成最终的聚合特征.
讲完图(c),继续看图(b)
生成最终的聚合特征之后,作者又利用了一个线性层,在通道方向上进行融合,生成的特征,作者称之为调制器
调制器可视化

作者还对调制器的值进行了可视化,可以看到,在重点区域的特征表示还是很准确的,这意味着调制器能够准确定位图像中重要位置的信息
(Figure 5) 是门控的可视化,可以看到随着尺度的增加,终点区域凸显的范围也是越来越大
最后调制器与Q矩阵进行点乘,以这样的形式进行交互,得到整个模块的输出
🚩 接下来理解这句话:在简介中 作者提到将聚合过程与单个query token解耦,显著简化的计算过程
我们来看上下文聚合模块,上下文聚合模块只需要执行一次,就可以生成多尺度的上下文信息,也就是这个调制器作为一个整体,与Q矩阵直接进行交互,效率很高,因为这样的话就不需要将Q矩阵中的每个query像素依次与其他像素进行交互和聚合
- 可行的修改: 门控生成方式,让每一层的尺度特征,通过Sigmoid函数生成权重,重新画图