快速视觉transformer,计算效率比较高,计算效率高的模块,最推荐应用了,因为计算效率高本身就是优点,然后迁移自己的模型当中去,至少训练是很快的,不会等待的很漫长
nips2022,机器学习三大会
简介
作者提出了一种简单有效的注意力机制: HiloAttention,其灵感来自于这样一种见解:即图像中的高频捕捉局部清晰细节, 低频专注于全局结构,而传统的自注意力机制忽略了不同频率的特征
开门见山,阐明动机:
图像中存在局部精细细节的高频特征以及全局结构的低频特征
(也还是局部和全局)
因此作者建议将注意力头分为两组,以此来区分注意力层中的高低频模式
从这句话中,我们能够获取三个信息
第一个信息,就是使用的是常见的注意力机制
第二个使用的是双分支并行结构来分别建模高低频模式
第三个双分支结构,通过分配注意力头来实现,简单来说就是分配不一样的通道数量
继续看,其中一组通过局部窗口自注意力来编码高频特征,另外一组通过全局注意力来编码低频特征,其中每个窗口通过平均池化,生成低频的case和values,输入特征图中的每个位置作为query
最后两句直接点明了作者的做法,分别是局部窗口自注意力和全局注意力机制
📍 HiLoAttention 局部性,全局性
📍 Dilatedformer 局部性和稀疏性
模型图
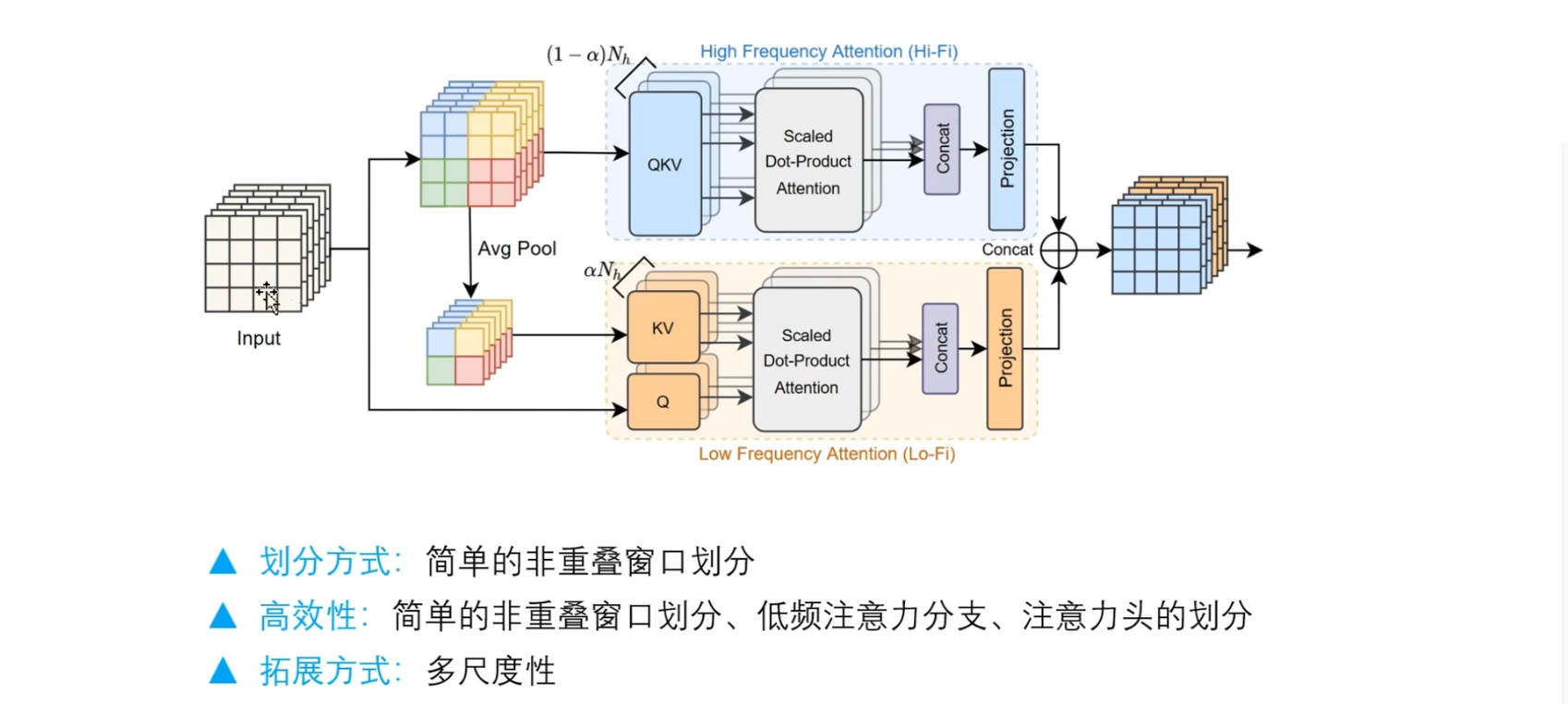
给定一个输入,首先划分窗口,这里的划分窗口,可以通过简单的reshape操作就可以实现,然后通过一个线性层来生成QKV表示,并汇入到缩放点积注意力模块中,然后将多个头的输出进行拼接,这一部分作者把它命名为高频注意力(上半部分) ,因为主要是捕捉图片中每个patch的局部精细细节, 也就是它周围的一个上下文信息
下面这个分支,它接受两个输入,分别是原始的输入来生成query表示,那么这个key和value矩阵,它是来源于划分后的窗口表示,也就是在这个reshape的基础上,执行下采样操作,也就是平均池化
那么这个池化的窗口大小,就是这个窗口注意力的大小,如图所示,共有 16 个像素点,每个窗口有4个像素点,就是每个颜色都代表一个窗口,设置池化窗口=4,池化完之后就只剩下了四个像素点
池化后的每个像素点,都具有原始窗口内的全局信息表示,以这样的方式,就可以得到很小的Key和Value矩阵,此时注意力矩阵可以从 $16×16$的注意力矩阵转变为 $16×4$ 的 shape(why?不懂)总之,平方的计算复杂度转变为线性复杂度,所以,计算效率就会得到很大的提高
这里的两个分支是有联系的,它们共享N个注意力头(?)
大家可以在实验中尝试一下,根据自己的任务判断哪个分支所起的作用最大,那么他就应该占用更多的注意力头,更多的通道数量
关于几个问题
🚩 第一个,为什么是简单的非重叠划分?
其他划分的方式,比如滑动窗口,窗口分区等等,因为它们实际上非常的耗费时间,即使在理论上有低复杂性的证明,但是这些方法不一定适配GPU, 这意味着效率是很低的
而这个简单的非重叠窗口划分反而是最有效的
🚩 第二个问题,高效性体现在哪里
第一个就是我们刚刚提到的简单的非重叠窗口划分,在效率方面,它优于其他的窗口划分方法
第二个就是我们的低频注意力分支,在这个低频注意力分支里面,可以通过设置窗口注意力的尺寸,就可以来实现更加高效的计算
🚩 第三个就是注意力头的划分
我们不需要将所有的通道分别输入到两个分支,而是通过分配注意力头的数量,来降低计算复杂度
那么第三个问题如何拓展呢
很显然,这里的窗口大小是固定的,会限制模型的学习能力,并且我们也不能确定哪一个窗口大小就是很合适的,所以说通过和多尺度相结合,堆叠多个这样的HiloAttention,就可以灵活的实现不同尺度的建模,同时性能好,效率高