挤压增强的轴向transformer
ICLR2023
简介
视觉transformer(ViT)的计算成本和内存消耗都很大,使得它们难以部署到移动设备上
动机
作者就是为了做一个轻量化的视觉transformer模型,能够部署在移动设备上的模型
方法
本文设计了一个挤压增强的轴向注意力机制,首先在特征图的水平和垂直方向上,通过压缩操作将全局信息保留到单个轴,然后分别用自注意力机制建模轴上的长程依赖,大大降低了计算复杂度
作者的做法还是熟悉的压缩操作,在讲的各种通道注意力机制中都存在
回顾 SENet
通过压缩全局空间信息来获取通道描述符
坐标注意力通过在H方向和W方向上分别压缩,来获得具有方向感知的通道描述符表示
通道注意力中一般压缩完之后,会通过Sigmoid函数来生成权重
在这篇论文, 作者也是在W方向上和H方向上分别压缩之后,应用自注意力机制建模长程依赖,这样的话相当于直接去掉了一个维度,那么在执行注意力机制的时候,复杂度肯定是降低了
对比坐标注意力
前半部分是一样的,后半部分是不一样的
(继续)接着看压缩操作,有效地提取了全局信息,但牺牲了局部细节
因此作者额外通过一个基于卷积的操作,来增强空间细节表示,实现了更好的性能和更低的延迟
压缩操作无论是平均池化还是最大池化,即使提取了最重要的信息,还是会不可避免地丢掉一部分的细节信息,因此作者在这里就是通过一个卷积操作,来提取局部信息,弥补了局部信息提取不足的缺陷
模型图
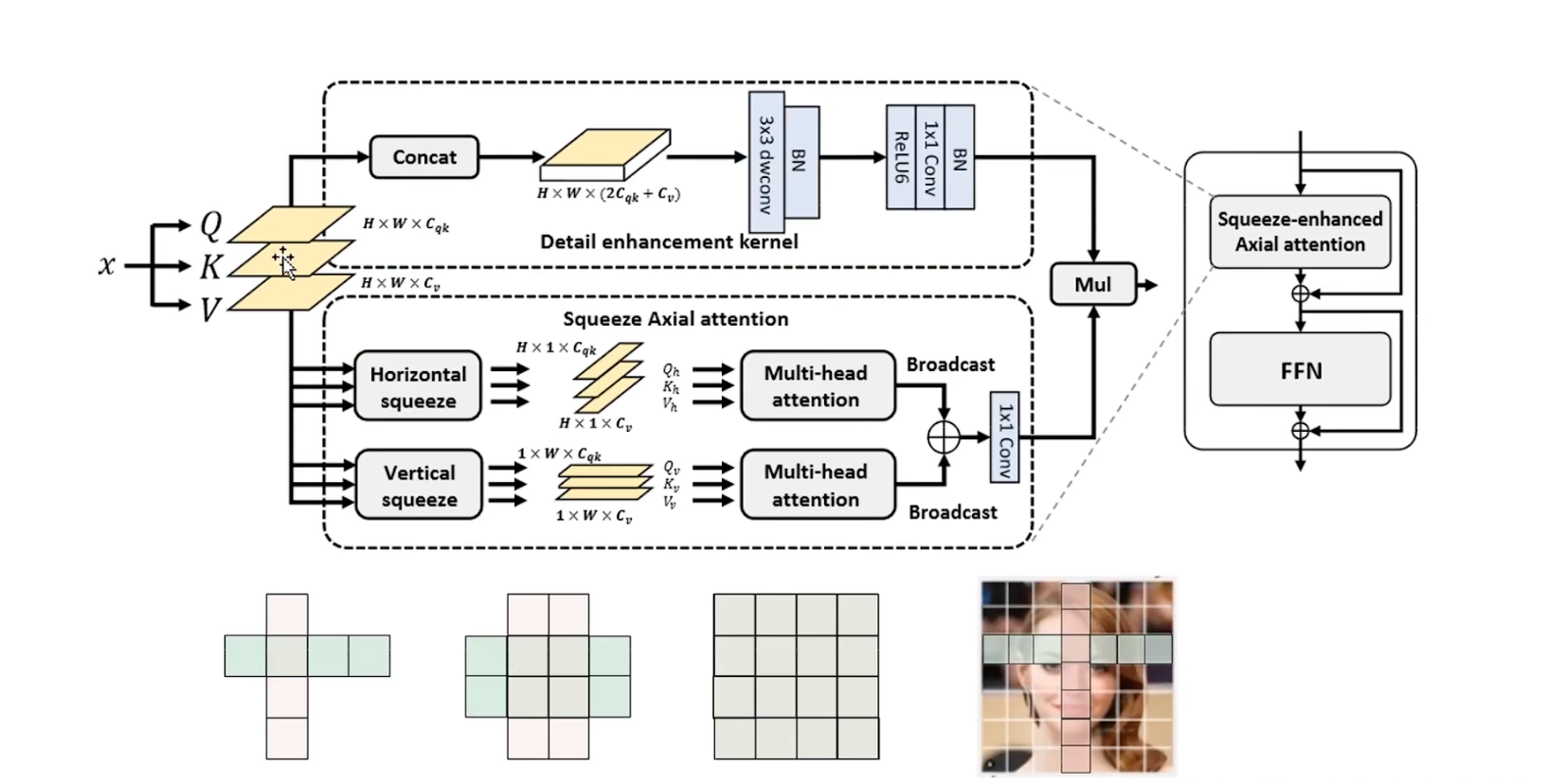
输入X, 得到QKV 3个矩阵表示
- 上半部分是细节增强的卷积操作
- 下半部分是挤压轴向注意力
先看挤压轴向注意力
首先在水平方向,也就是 W 方向进行压缩操作,图中有三个箭头,也就是对 QKV 都进行压缩,得到的 shape 是 $H×1×C$ ,接着在 $H$ 方向,执行多头注意力机制,捕捉$H$方向上的长期依赖性,这里的注意力机制也是原始的注意力,没有使用任何的变体
垂直方向也是一样的道理,在$H$方向上进行压缩得到的shape, 就是 $1×W×C$, 然后在 $W$ 方向执行多头注意力,捕捉W 方向的长期依赖
最后将两部分输出进行相加,和坐标注意力的思想很类似
相加完之后,在图片的每一个像素点上,都能同时具有$H$轴上的位置特征和$W$轴上的一个位置特征
补充:
shape 不同,可以广播
首先忽略掉通道维度,两个向量分别是 $H×1$ (图中所示粉色向量)和 $1×W$ (绿色向量), 可以互相扩充到相应的维度, 具体来说,
粉色向量,复制 4 份,使得和绿色向量的长度保持一致
同样绿色的向量也会复制四份,和粉色向量的高度保持一致
这样就可以相加了
经过这样复制相加,每一个像素点上都具有了$H$方向上的特征,还有 $W$ 方向上的特征,也就是每个像素点都具有了独一无二的特征表示
对于同一行的像素点来说,$W$方向,也就是 $X$ 方向上的特征是不同的,但是是处于同一高度的,也就是说$Y$坐标是相同的,因此$H$方向的特征是相同的
同样对同一列的像素点来说,H方向上的特征是不同的,但是由于它们的$X$坐标是相同的,因此在$W$方向上的特征就是相同的
以上是一个完整的轴向注意力
上半部分:细节增强的轴向卷积
作者通过将QKV,在通道上进行拼接,得到的是张量形状 $H×W×(2C_{qk}+C_v)$
然后通过3×3的卷积, 来提取局部特征,从而来增强局部细节感知,最后通过一个1×1的卷积层,将维度降低到降维到C,与下面这个分支的维度要保持一致
最后进行简单的融合,得到输出特征
总结
作者学习了坐标注意力的思想,为图片中的每个像素,都单独学习一个横向特征和一个纵向特征表示,从而来保证每一个像素点特征的唯一性
启示
只要你拥有两个特征维度,可以按照坐标的这个概念来寻找切入点